第09章:上下文与记忆
讲师:尚硅谷-宋红康
官网:尚硅谷
1、概述
1.1 为什么需要记忆(Memory)
记忆是一种记住之前互动信息的系统。随着Agent处理涉及大量用户交互的复杂任务,记忆变得至关重要!
大多数的大模型应用程序都会有一个会话接口,允许我们进行多轮的对话,并有一定的上下文记忆能力。比如:
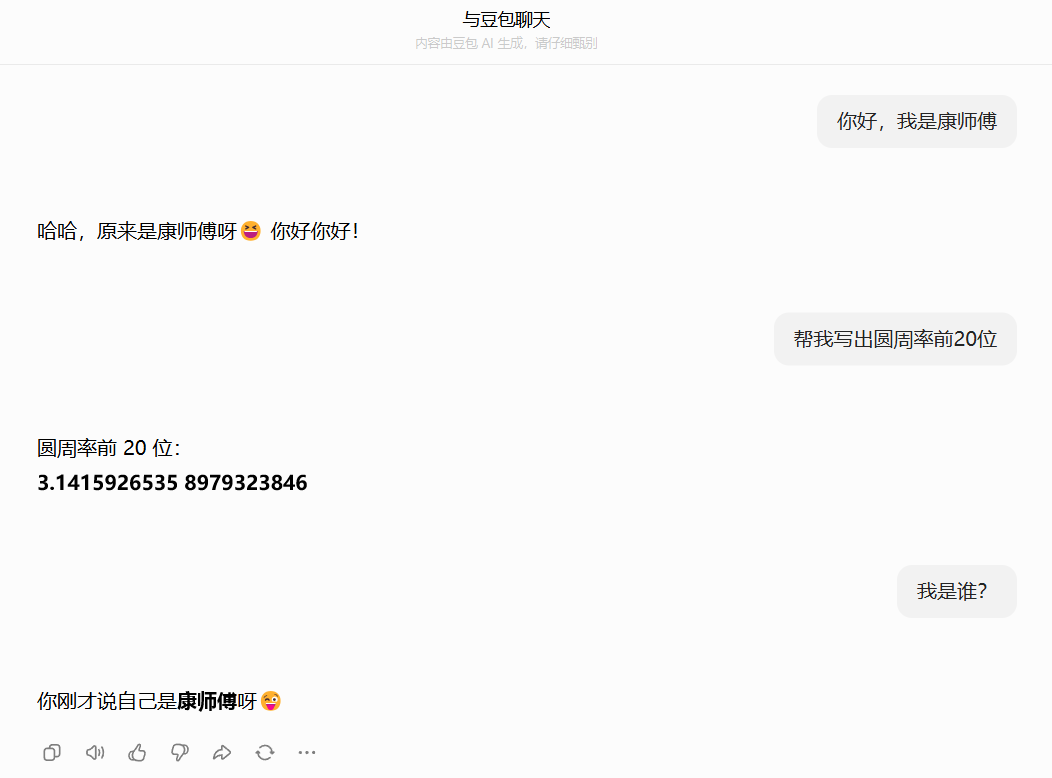
但实际上,大模型本身是“无状态”的,不会记忆任何上下文的。即每次调用 agent.invoke() 都是全新的开始,不记得之前的对话。
举例:
from langchain.chat_models import init_chat_model
from dotenv import load_dotenv
import os
# 从.env文件中加载环境变量
load_dotenv(override=True)
model = init_chat_model(
model="gpt-5.4-mini",
model_provider="openai",
api_key=os.getenv("CLOSEAI_API_KEY"),
base_url=os.getenv("CLOSEAI_BASE_URL")
)
情况1:
from langchain.agents import create_agent
from langchain_core.messages import HumanMessage, AIMessage
messages1 = [
HumanMessage("你好,我叫小明"),
AIMessage("很高兴认识你,小明"),
HumanMessage("你用一句话介绍下你自己"),
]
agent = create_agent(
model=model,
tools=[],
)
response1 = agent.invoke({"messages" : messages1})
for msg in response1["messages"]:
msg.pretty_print()
================================ Human Message
=================================
你好,我叫小明
================================== Ai Message
==================================
很高兴认识你,小明
================================ Human Message
=================================
你用一句话介绍下你自己
================================== Ai Message
==================================
我是一个可以帮助你回答问题、写作、翻译和思考的 AI 助手。
messages2 = [HumanMessage("我叫什么名字?")]
response2 = agent.invoke({"messages" : messages2})
for msg in response2["messages"]:
msg.pretty_print()
================================ Human Message
=================================
我叫什么名字?
================================== Ai Message
==================================
我不知道你的名字,除非你告诉我。
如果你愿意,可以直接告诉我,我就记住并称呼你。
情况2:
messages3 = [
HumanMessage("你好,我叫小明"),
AIMessage("很高兴认识你,小明"),
HumanMessage("你用一句话介绍下你自己"),
AIMessage("我是一个由 OpenAI 训练的人工智能助手,可以帮你回答问题、写作和解决各种任
务。"),
HumanMessage("我叫什么名字?")
]
response3 = agent.invoke({"messages" : messages3})
for msg in response3["messages"]:
msg.pretty_print()
================================ Human Message
=================================
你好,我叫小明
================================== Ai Message
==================================
很高兴认识你,小明
================================ Human Message
=================================
你用一句话介绍下你自己
================================== Ai Message
==================================
我是一个由 OpenAI 训练的人工智能助手,可以帮你回答问题、写作和解决各种任务。
================================ Human Message
=================================
我叫什么名字?
================================== Ai Message
==================================
你叫小明。
我们希望的智能体应该是右图的情况:
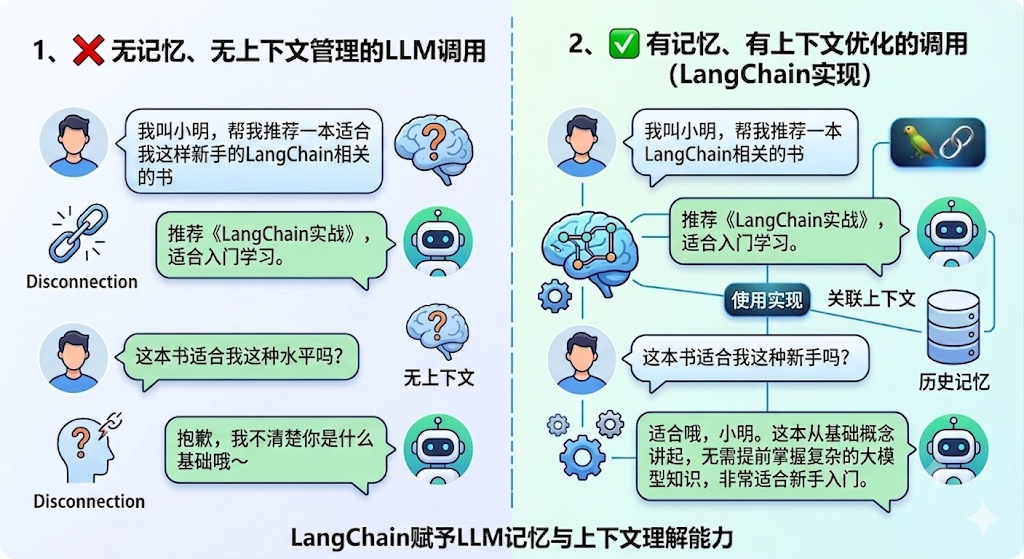
1.2 如何解决记忆问题
1.2.1 上下文工程
实现这个记忆功能,就需要额外的模块去保存我们和模型对话的上下文信息,然后在下一次请求时,把历史信息都输入给模型,让模型输出结果。
在 LangChain 中,记忆(Memory) 就是专门负责“ 存储历史交互信息”的组件,核心作用是「保存上下文」和「提供上下文」,让LLM在每次响应时,都能“看到”之前的对话内容。
上下文工程(Context Engineering) 负责“合理组织”这些记忆和任务信息,让LLM的响应更连贯、更贴
合需求。这也是Agent能实现复杂多轮交互的核心基础。
类比:
举例:

1.2.2 上下文类型及相关的API
LangChain的上下文工程是基于Agent讨论的,而上下文工程是构建在LangGraph之上的。
LangGraph 提供了三种管理上下文的方法,这些方法结合了可变性和生命周期维度:
1.3 LangChain的记忆
1.3.1 记忆的分类
官方说明:https://docs.langchain.com/oss/python/concepts/memory
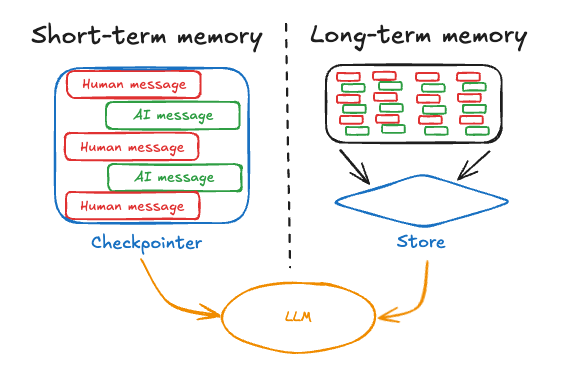
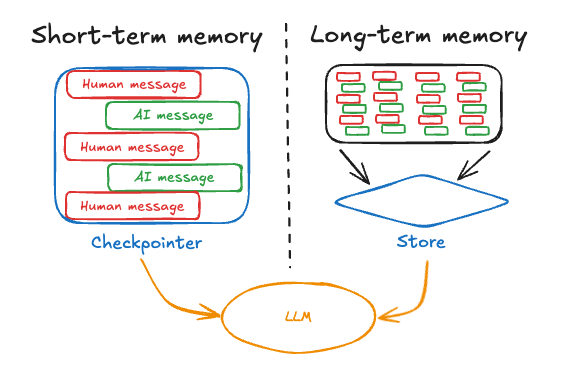
记忆分为短期记忆和长期记忆,对应不同的使用场景:
短期记忆(Short-term memory、会话级记忆、thread-scoped memory):作用范围是单个对话线程(Thread)内,一旦开启新对话(更换 thread_id ),记忆即消失。
长期记忆(Long-term memory,跨会话级记忆 ):在会话间存储用户特定或应用级数据, 并在会话线程间共享。它可以随时在任何线程中被调用。记忆的范围是任意自定义命名空间,而不仅仅是单一线程 ID。
1.3.2 记忆的管理
在LangChain v0.x版本中,通过专用的xxxMemory类管理记忆。
在LangChain v1.x版本中,Agent是构建在LangGraph图结构之上的,通过上文提到的state和store构建记忆系统。使用更简单、功能更统一。
state:短期记忆对象,以会话为单位组织,包含当前会话的所有消息记录以及自定义信息。
store:长期记忆对象,跨会话持久化的数据,通常需要结合向量数据库或外部存储实现。
2、短期记忆
LangChain1.x 的短期记忆是三者的组合:
State(会话内部状态) + Checkpointer(持久化机制) + Thread ID(会话作用域)
State :默认存储历史消息列表messages ,通过State 管理历史消息Checkpointer :负责将State 作为检查点持久化保存,检查点是某个时刻的State 快照Thread ID :用于唯一标识State ,LangChain运行时会按照 thread_id 读写State快照
这就像玩 RPG 游戏时的“自动存档”:你不需要手动保存,系统在关键节点自动记录,下次进入游戏随时可以从上次的存档点继续。
2.1 基于内存的持久化器
这是最便捷的使用方式,适合快速测试或调试。
2.1.1 举例1:没有记忆
from langchain.agents import create_agent
from langchain.messages import HumanMessage
agent = create_agent(
model=model,
tools=[]
)
print("\n第一轮对话:")
response1 = agent.invoke({
"messages": [HumanMessage("我叫张三")]
})
print(f"Agent: {response1['messages'][-1].content}")
print("\n第二轮对话:")
response2 = agent.invoke({
"messages": [HumanMessage("我叫什么?")]
})
print(f"Agent: {response2['messages'][-1].content}")
第一轮对话:
Agent: 你好,张三!很高兴认识你。有什么我可以帮你的吗?
第二轮对话:
Agent: 我不知道你的名字,除非你告诉我。
如果你愿意,可以直接发给我,我就能记住在这次对话里称呼你。
2.1.2 举例2:拥有记忆
步骤1:第一二轮对话
from langgraph.checkpoint.memory import InMemorySaver
checkpointer = InMemorySaver()
# 1. 创建 Agent 时添加 checkpointer
agent = create_agent(
model=model,
checkpointer=checkpointer # 添加内存管理
)
# 2. 调用时指定 thread_id
config = {
"configurable": {
"thread_id": "1"
}
}
print("\n第一轮对话:")
response1 = agent.invoke({
"messages": [HumanMessage("我叫张三")]},
config=config # 传入 config
)
print(f"Agent: {response1['messages'][-1].content}")
print("\n第二轮对话:")
response2 = agent.invoke({
"messages": [HumanMessage("我叫什么?")]},
config=config # 使用相同的 thread_id
)
print(f"Agent: {response2['messages'][-1].content}")
第一轮对话:
Agent: 你好,张三!很高兴认识你。有什么我可以帮你的吗?
第二轮对话:
Agent: 你叫张三。
说明:你只需传入 checkpointer 和 config,Agent 就能自然具备连续对话能力。
from rich import print as rprint
latest_state = agent.get_state(config)
rprint(latest_state)
StateSnapshot(
values={
'messages': [
HumanMessage(
content='我叫张三',
additional_kwargs={},
response_metadata={},
id='16672c9b-4fac-44ca-830d-12908bad2c59'
),
AIMessage(
content='你好,张三!很高兴认识你。有什么我可以帮你的吗?',
additional_kwargs={'refusal': None},
response_metadata={
'token_usage': {
'completion_tokens': 22,
'prompt_tokens': 10,
'total_tokens': 32,
'completion_tokens_details': {
'accepted_prediction_tokens': 0,
'audio_tokens': 0,
'reasoning_tokens': 0,
'rejected_prediction_tokens': 0
},
'prompt_tokens_details': {'audio_tokens': 0,
'cached_tokens': 0},
'latency_checkpoint': {
'engine_tbt_ms': 5,
'engine_ttft_ms': 52,
'engine_ttlt_ms': 155,
'pre_inference_ms': 80,
'service_tbt_ms': 5,
'service_ttft_ms': 696,
'service_ttlt_ms': 792,
'total_duration_ms': 721,
'user_visible_ttft_ms': 616
}
},
'model_provider': 'openai',
'model_name': 'gpt-5.4-mini-2026-03-17',
'system_fingerprint': None,
'id': 'chatcmpl-DpDsXsSSbHRvHJlJ42b19uMDGKRGQ',
'service_tier': 'default',
'finish_reason': 'stop',
'logprobs': None
},
id='lc_run--019eb1db-f785-79a1-b52a-d3b718e5b1da-0',
tool_calls=[],
invalid_tool_calls=[],
usage_metadata={
'input_tokens': 10,
'output_tokens': 22,
'total_tokens': 32,
'input_token_details': {'audio': 0, 'cache_read': 0},
'output_token_details': {'audio': 0, 'reasoning': 0}
}
),
HumanMessage(
content='我叫什么?',
additional_kwargs={},
response_metadata={},
id='ea385d96-ba1e-4b40-9b53-9e2848f751f0'
),
AIMessage(
content='你叫张三。',
additional_kwargs={'refusal': None},
response_metadata={
'token_usage': {
'completion_tokens': 9,
'prompt_tokens': 41,
'total_tokens': 50,
'completion_tokens_details': {
'accepted_prediction_tokens': 0,
'audio_tokens': 0,
'reasoning_tokens': 0,
'rejected_prediction_tokens': 0
},
'prompt_tokens_details': {'audio_tokens': 0,
'cached_tokens': 0},
'latency_checkpoint': {
'engine_tbt_ms': 3,
'engine_ttft_ms': 38,
'engine_ttlt_ms': 64,
'pre_inference_ms': 96,
'service_tbt_ms': 4,
'service_ttft_ms': 295,
'service_ttlt_ms': 310,
'total_duration_ms': 227,
'user_visible_ttft_ms': 199
}
},
'model_provider': 'openai',
'model_name': 'gpt-5.4-mini-2026-03-17',
'system_fingerprint': None,
'id': 'chatcmpl-DpDsYCdO16maB6yakkiFJknskxd0C',
'service_tier': 'default',
'finish_reason': 'stop',
'logprobs': None
},
id='lc_run--019eb1dc-0139-7cc3-bd9a-1d608b2fd48f-0',
tool_calls=[],
invalid_tool_calls=[],
usage_metadata={
'input_tokens': 41,
'output_tokens': 9,
'total_tokens': 50,
'input_token_details': {'audio': 0, 'cache_read': 0},
'output_token_details': {'audio': 0, 'reasoning': 0}
}
)
]
},
next=(),
config={
'configurable': {
'thread_id': '1',
'checkpoint_ns': '',
'checkpoint_id': '1f164d5b-625c-679d-8004-1ef8a3347091'
}
},
metadata={'source': 'loop', 'step': 4, 'parents': {}},
created_at='2026-06-10T14:07:27.193684+00:00',
parent_config={
'configurable': {
'thread_id': '1',
'checkpoint_ns': '',
'checkpoint_id': '1f164d5b-570f-6b8f-8003-88f1894a5042'
}
},
tasks=(),
interrupts=()
)
步骤2:第三轮对话
当我们再次进行对话时,直接带入线程ID,即可带入此前对话记忆:
print("\n第三轮对话:")
response3 = agent.invoke({
"messages": [HumanMessage("我刚才问了什么问题?")]},
config=config # 使用相同的 thread_id
)
print(f"Agent: {response3['messages'][-1].content}")
第三轮对话:
Agent: 你刚才问的是:“我叫什么?”
from rich import print as rprint
latest_state = agent.get_state(config)
rprint(latest_state)
输出:略
说明:第三轮对话中的 "我刚才问了什么问题?" 就能在第二轮存储的消息历史中找到答案。所有消息历史都会自动追加到 AgentState 的 messages 字段中,无需手动维护。
步骤3:更新线程ID
而如果更新线程ID,则会重新开启对话:
config2 = {
"configurable": {
"thread_id": "2"
}
}
response4 = agent.invoke(
{"messages": [HumanMessage("你还记得我叫什么名字么?")]},
config=config2
)
print(response4['messages'][-1].content)
我目前**不知道你的名字**,因为你还没有告诉我。
如果你愿意,可以直接发我你的名字,我就用这个称呼你。
说明:thread_id 隔离不同会话空间。
2.1.3 关键步骤说明
第1步:初始化记忆引擎:checkpointer = InMemorySaver() ——创建一个内存级的记忆存储。
注意:InMemorySaver内存中保存,进程结束就丢失数据,适合测试。生产环境可换成数据库持久化的 SqliteSaver 、PostgresSaver 等
第2步:绑定 Agent:在 create_agent 时传入 checkpointer ,让 Agent 具备状态存储能力。
第3步:设定会话 ID:通过 config = {"configurable": {"thread_id": "1"}} 为每次调用指定线程标识。
同一个 thread_id 共享记忆,不同 thread_id 完全隔离。
# 会话 1
config1 = {"configurable": {"thread_id": "1"}}
agent.invoke({...}, config=config1)
# 会话 2
config2 = {"configurable": {"thread_id": "2"}}
agent.invoke({...}, config=config2)
# 两个会话完全独立
thread_id 是记忆管理的核心开关:在会话2里询问会话1的会话信息,Agent 会表示不知道——因为双
方记忆空间完全隔离。
生产环境中:
场景1:多用户聊天
不同 thread_id = 不同会话,Agent 能正确记住每个会话的内容。
agent = create_agent(
model=model,
tools=[],
checkpointer=InMemorySaver()
)
# 用户 Alice
config_alice = {"configurable": {"thread_id": "user_alice"}}
agent.invoke({"messages": [...]}, config_alice)
...
# 用户 Bob
config_bob = {"configurable": {"thread_id": "user_bob"}}
agent.invoke({"messages": [...]}, config_bob)
...
# 两个会话完全独立
场景2:同一用户的不同任务
# 任务 1:写代码
config_task1 = {"configurable": {"thread_id": "task_coding"}}
agent.invoke({"messages": [...]}, config_task1)
...
# 任务 2:写文档
config_task2 = {"configurable": {"thread_id": "task_docs"}}
agent.invoke({"messages": [...]}, config_task2)
...
2.1.4 工作原理
内存保存了什么?
agent.invoke({"messages": [{"role": "user", "content": "你好"}]}, config)
# InMemorySaver 保存:
# {
# "thread_id": "xxx",
# "messages": [
# HumanMessage("你好"),
# AIMessage("你好!有什么可以帮助你的吗?")
# ]
# }
agent.invoke({"messages": [{"role": "user", "content": "天气"}]}, config)
# InMemorySaver 更新:
# {
# "thread_id": "xxx",
# "messages": [
# HumanMessage("你好"),
# AIMessage("你好!有什么可以帮助你的吗?"),
# HumanMessage("天气"),
# AIMessage("...")
# ]
# }
自动追加历史
# 你只需要传新消息
agent.invoke(
{"messages": [{"role": "user", "content": "新问题"}]},
config
)
此时,checkpointer 自动:
① 读取之前的历史
② 追加新消息
③ 调用模型(传入完整历史)
④ 保存新的历史
说明:checkpointer 会自动管理历史
2.1.5 常见问题
1、为什么 Agent 不记得?
检查:
✅ 是否传入了 config 参数?
agent = create_agent(model=model, tools=[])
agent.invoke({...}) # 不会记住
agent = create_agent(model=model, tools=[], checkpointer=InMemorySaver())
agent.invoke({...}) # 不会记住
agent.invoke({...}, config={"configurable": {"thread_id": "1"}})
agent.invoke({...}, config={"configurable": {"thread_id": "2"}}) # 不同会话
agent = create_agent(model=model, tools=[], checkpointer=InMemorySaver())
config = {"configurable": {"thread_id": "1"}}
agent.invoke({...}, config)
agent.invoke({...}, config) # 记得!
2、InMemorySaver 会丢失数据吗?
会! InMemorySaver 只保存在内存中:
✅ 同一进程内有效(不支持跨进程共享)
❌ 程序重启后丢失(或进程重启后丢失)
❌ 不同进程无法共享
解决方案:持久化(SQLite、PostgreSQL)
3、内存会无限增长吗?
会! 默认情况下,InMemorySaver 会保存所有消息。
问题:
消息越来越多(无限增长,需要管理上下文)
token消耗增加,甚至会超过模型的 token 限制响应速度变慢、成本增加
解决方案:上下文管理(修剪、摘要)
4、如何清空某个会话的历史?
目前 InMemorySaver 没有提供删除 API。
临时方案:
使用新的 thread_id或重新创建 Agent
2.2 基于外部存储介质的持久化器
如果将状态检查点(checkpointer) 保存在内存,进程结束则状态丢失,生产环境不可接受。因此,生产环境要用持久化的外部存储介质,如PostgreSQL。LangGraph提供的checkpointer后端列表如下
https://docs.langchain.com/oss/python/langgraph/persistence#checkpointer-libraries
此处选择PostgreSQL作为持久化器。
2.2.1 数据库环境准备
在此之前,先准备好PostgreSQL环境,此处在云服务器的Ubuntu系统安装PostgreSQL。大家需要根据自己云服务器位置,更改URL中的IP即可。
具体云服务器安装和PostgreSQL的安装,见文件02-资料下的《Linux云服务器安装与PostgreSQL安装》
URL:
postgresql://langchain_user:abcd1234@118.195.128.47:5432/langchain_db?
sslmode=disable
说明:
1、上述URL中的用户名、密码、IP地址,需要根据自己的情况替换。
2、要在LangChain中对接PostgreSQL,还需要额外的依赖,比如:
pip install langgraph-checkpoint-postgres
其实我们在课程开始的requirements.txt中已经提供了相关依赖,此处不必也不能重新安装,否则版本可能冲突。
2.2.2 代码实现
from langchain.chat_models import init_chat_model
from dotenv import load_dotenv
import os
# 从.env文件中加载环境变量
load_dotenv(override=True)
model = init_chat_model(
model="gpt-5.4-mini",
model_provider="openai",
api_key=os.getenv("CLOSEAI_API_KEY"),
base_url=os.getenv("CLOSEAI_BASE_URL")
)
from langchain.agents import create_agent
from langchain.messages import HumanMessage
from langgraph.checkpoint.postgres import PostgresSaver
DB_URL =
"postgresql://langchain_user:abcd1234@118.195.128.47:5432/langchain_db?
sslmode=disable"
with PostgresSaver.from_conn_string(DB_URL) as checkpointer:
# 初始化PostgreSQL数据库
checkpointer.setup()
agent = create_agent(
model=model,
checkpointer=checkpointer
)
config = {"configurable": {"thread_id": "1"}}
response1 = agent.invoke(
{"messages": [HumanMessage("你好,我是老王")]},
config=config
)
print("=" * 30, "-> 第一次调用 <-", "=" * 30)
for msg in response1["messages"]:
msg.pretty_print()
response2 = agent.invoke(
{"messages": [HumanMessage("你好,我是谁?")]},
config=config
)
print("=" * 30, "-> 第二次调用 <-", "=" * 30)
for msg in response2["messages"]:
msg.pretty_print()
输出
============================== -> 第一次调用 <-
==============================
================================ Human Message
=================================
你好,我是老王
================================== Ai Message
==================================
你好,老王!很高兴认识你。有什么我可以帮你的?
============================== -> 第二次调用 <-
==============================
================================ Human Message
=================================
你好,我是老王
================================== Ai Message
==================================
你好,老王!很高兴认识你。有什么我可以帮你的?
================================ Human Message
=================================
你好,我是谁?
================================== Ai Message
==================================
你是老王。
setup() 用于初始化PostgreSQL数据库,首次运行会创建必要的表,重复执行不会重新建表,底层逻辑
是Create IF Not Exists ,相关源码如下
def setup(self) -> None:
"""Set up the checkpoint database asynchronously.
This method creates the necessary tables in the Postgres database if they
don't already exist and runs database migrations. It MUST be called directly
by the user the first time checkpointer is used.
"""
...
2.2.3 查看持久化数据
查看PostgreSQL数据库,可以通过命令行或图形化工具查看
ubuntu@VM-0-6-ubuntu:~$ psql
"postgresql://langchain_user:abcd1234@localhost:5432/langchain_db?
sslmode=disable"
psql (16.13 (Ubuntu 16.13-0ubuntu0.24.04.1))
Type "help" for help.
langgraph_db=>
PostgreSQL的存储结构是Database -> Schema -> Table
Table :表
需求1:查看所有数据库
langgraph_db=> \l
List of
databases
Name | Owner | Encoding | Locale Provider | Collate |
Ctype | ICU Locale | ICU Rules | Access privileges
--------------+----------------+----------+-----------------+---------+-----
----+------------+-----------+-----------------------------------
langgraph_db | langgraph_user | UTF8 | libc | C.UTF-8 |
C.UTF-8 | | | =Tc/langgraph_user +
| | | | |
| | | langgraph_user=CTc/langgraph_user
postgres | postgres | UTF8 | libc | C.UTF-8 |
C.UTF-8 | | |
template0 | postgres | UTF8 | libc | C.UTF-8 |
C.UTF-8 | | | =c/postgres +
| | | | |
| | | postgres=CTc/postgres
template1 | postgres | UTF8 | libc | C.UTF-8 |
C.UTF-8 | | | =c/postgres +
| | | | |
| | | postgres=CTc/postgres
(4 rows)
命令行前缀langgraph_db 标识了当前所在数据库
需求2:查看所有schema
langgraph_db=> \dn
List of schemas
Name | Owner
--------+-------------------
public | pg_database_owner
(1 row)
需求3:查看当前所处的schema
langgraph_db=> select current_schema();
current_schema
----------------
public
(1 row)
需求4:查看当前schema下的所有表
langgraph_db=> \dt
List of relations
Schema | Name | Type | Owner
--------+-----------------------+-------+----------------
public | checkpoint_blobs | table | langgraph_user
public | checkpoint_migrations | table | langgraph_user
public | checkpoint_writes | table | langgraph_user
public | checkpoints | table | langgraph_user
(4 rows)
这四张表都是setup() 函数初始化时创建的。
checkpoints :这是主表,存每个 thread 在某个时刻的 checkpoint 快照。
checkpoint_blobs :这张表专门存不适合直接内联进 checkpoints.checkpoint 的较复杂
channel 值。
checkpoint_writes :这张表存的是中间写入 / pending writes,不是最终完整 checkpoint。
checkpoint_migrations :这张表不是业务数据表,而是迁移版本表。
2.3 对比两种方式
举例1:基于内存存储
from langchain.agents import create_agent
from langchain.messages import HumanMessage
from langgraph.checkpoint.memory import InMemorySaver
agent = create_agent(
model=model,
checkpointer=InMemorySaver()
)
config = {"configurable": {"thread_id": "1"}}
print("=" * 30, "-> 第一次调用 <-", "=" * 30)
response1 = agent.invoke(
{"messages": [HumanMessage("你好,我是谁?")]},
config=config
)
for msg in response1["messages"]:
msg.pretty_print()
print("=" * 30, "-> 第二次调用 <-", "=" * 30)
response2 = agent.invoke(
{"messages": [HumanMessage("我是老王")]},
config=config
)
for msg in response2["messages"]:
msg.pretty_print()
print("=" * 30, "-> 第三次调用 <-", "=" * 30)
response3 = agent.invoke(
{"messages": [HumanMessage("你好,我是谁?")]},
config
)
for msg in response3["messages"]:
msg.pretty_print()
输出如下
============================== -> 第一次调用 <-
==============================
================================ Human Message
=================================
你好,我是谁?
================================== Ai Message
==================================
你好!我不知道你的真实身份,除非你告诉我。
如果你愿意,我可以根据你提供的信息,帮你判断你是谁、你像哪类人,或者帮你整理一段自我介
绍。
============================== -> 第二次调用 <-
==============================
================================ Human Message
=================================
你好,我是谁?
================================== Ai Message
==================================
你好!我不知道你的真实身份,除非你告诉我。
如果你愿意,我可以根据你提供的信息,帮你判断你是谁、你像哪类人,或者帮你整理一段自我介
绍。
================================ Human Message
=================================
我是老王
================================== Ai Message
==================================
你好,老王!很高兴认识你。
如果你愿意,我可以直接这样称呼你。
============================== -> 第三次调用 <-
==============================
================================ Human Message
=================================
你好,我是谁?
================================== Ai Message
==================================
你好!我不知道你的真实身份,除非你告诉我。
如果你愿意,我可以根据你提供的信息,帮你判断你是谁、你像哪类人,或者帮你整理一段自我介
绍。
================================ Human Message
=================================
我是老王
================================== Ai Message
==================================
你好,老王!很高兴认识你。
如果你愿意,我可以直接这样称呼你。
================================ Human Message
=================================
你好,我是谁?
================================== Ai Message
==================================
你好,老王。你是老王。
可以发现,每次执行的输出完全相同,而我们并没有更改thread_id ,之所以看不到上次运行的状态是因为每次运行创建新的Saver(),历史State被丢弃了。
举例2:基于外部存储器存储
from langchain.agents import create_agent
from langchain.messages import HumanMessage
from langgraph.checkpoint.postgres import PostgresSaver
DB_URL =
"postgresql://langchain_user:abcd1234@118.195.128.47:5432/langchain_db?
sslmode=disable"
with PostgresSaver.from_conn_string(DB_URL) as checkpointer:
# 初始化数据库
checkpointer.setup()
agent = create_agent(
model=model,
checkpointer=checkpointer
)
config = {"configurable": {"thread_id": "3"}}
print("=" * 30, "-> 第一次调用 <-", "=" * 30)
response1 = agent.invoke(
{"messages": [HumanMessage("你好,我是谁啊?")]},
config
)
for msg in response1["messages"]:
msg.pretty_print()
print("=" * 30, "-> 第二次调用 <-", "=" * 30)
response2 = agent.invoke(
{"messages": [HumanMessage("我是老王~")]},
config
)
for msg in response2["messages"]:
msg.pretty_print()
print("=" * 30, "-> 第三次调用 <-", "=" * 30)
response3 = agent.invoke(
{"messages": [HumanMessage("你好,我是谁??")]},
config
)
for msg in response3["messages"]:
msg.pretty_print()
第一次输出:
============================== -> 第一次调用 <-
==============================
================================ Human Message
=================================
你好,我是谁啊?
================================== Ai Message
==================================
你好!我只能知道:你现在是这次和我对话的用户。
如果你是想问“我记不记得你是谁”,那我其实**不会自动知道你的真实身份**,除非你在对话里
告诉我。
你可以直接告诉我你想让我怎么称呼你。
============================== -> 第二次调用 <-
==============================
================================ Human Message
=================================
你好,我是谁啊?
================================== Ai Message
==================================
你好!我只能知道:你现在是这次和我对话的用户。
如果你是想问“我记不记得你是谁”,那我其实**不会自动知道你的真实身份**,除非你在对话里
告诉我。
你可以直接告诉我你想让我怎么称呼你。
================================ Human Message
=================================
我是老王~
================================== Ai Message
==================================
你好,老王~ 很高兴认识你!
接下来我可以怎么帮你?
============================== -> 第三次调用 <-
==============================
================================ Human Message
=================================
你好,我是谁啊?
================================== Ai Message
==================================
你好!我只能知道:你现在是这次和我对话的用户。
如果你是想问“我记不记得你是谁”,那我其实**不会自动知道你的真实身份**,除非你在对话里
告诉我。
你可以直接告诉我你想让我怎么称呼你。
================================ Human Message
=================================
我是老王~
================================== Ai Message
==================================
你好,老王~ 很高兴认识你!
接下来我可以怎么帮你?
================================ Human Message
=================================
你好,我是谁??
================================== Ai Message
==================================
你好,老王 🙂
第二次运行输出
============================== -> 第一次调用 <-
==============================
================================ Human Message
=================================
你好,我是谁啊?
================================== Ai Message
==================================
你好!我只能知道:你现在是这次和我对话的用户。
如果你是想问“我记不记得你是谁”,那我其实**不会自动知道你的真实身份**,除非你在对话
里告诉我。
你可以直接告诉我你想让我怎么称呼你。
================================ Human Message
=================================
我是老王~
================================== Ai Message
==================================
你好,老王~ 很高兴认识你!
接下来我可以怎么帮你?
================================ Human Message
=================================
你好,我是谁??
================================== Ai Message
==================================
你好,老王 🙂
================================ Human Message
=================================
你好,我是谁啊?
================================== Ai Message
==================================
你好,老王。
============================== -> 第二次调用 <-
==============================
================================ Human Message
=================================
你好,我是谁啊?
================================== Ai Message
==================================
你好!我只能知道:你现在是这次和我对话的用户。
如果你是想问“我记不记得你是谁”,那我其实**不会自动知道你的真实身份**,除非你在对话
里告诉我。
你可以直接告诉我你想让我怎么称呼你。
================================ Human Message
=================================
我是老王~
================================== Ai Message
==================================
你好,老王~ 很高兴认识你!
接下来我可以怎么帮你?
================================ Human Message
=================================
你好,我是谁??
================================== Ai Message
==================================
你好,老王 🙂
================================ Human Message
=================================
你好,我是谁啊?
================================== Ai Message
==================================
你好,老王。
================================ Human Message
=================================
我是老王~
================================== Ai Message
==================================
你好,老王~ 有什么我可以帮你的?
============================== -> 第三次调用 <-
==============================
================================ Human Message
=================================
你好,我是谁啊?
================================== Ai Message
==================================
你好!我只能知道:你现在是这次和我对话的用户。
如果你是想问“我记不记得你是谁”,那我其实**不会自动知道你的真实身份**,除非你在对话
里告诉我。
你可以直接告诉我你想让我怎么称呼你。
================================ Human Message
=================================
我是老王~
================================== Ai Message
==================================
你好,老王~ 很高兴认识你!
接下来我可以怎么帮你?
================================ Human Message
=================================
你好,我是谁??
================================== Ai Message
==================================
你好,老王 🙂
================================ Human Message
=================================
你好,我是谁啊?
================================== Ai Message
==================================
你好,老王。
================================ Human Message
=================================
我是老王~
================================== Ai Message
==================================
你好,老王~ 有什么我可以帮你的?
================================ Human Message
=================================
你好,我是谁??
================================== Ai Message
==================================
你好,老王。
根据输出判断,状态是累积的。
由此可以得出结论:即便重新创建Saver() ,只要thread_id 一致,历史状态就可以和当前调用串联起来。
总结:
- InMemorySaver()将状态持久化到内存,进程结束或重建Saver() 则历史状态丢失2. 基于外部存储介质(如PostgreSQL)的持久化器,其存储的状态不会随进程终止而丢失,只要不显式删除历史状态,即可通过thread_id 加载历史状态。
2.4 记忆治理策略(上下文管理)
随着对话的进行,历史消息不断累积,state会持续增长,为模型带来挑战:
- LLM的上下文窗口是有限的,完整历史可能无法装入LLM的上下文窗口,导致上下文丢失或错误。
- 即便模型的上下文窗口够大,多数LLM在长上下文场景仍然表现不佳。模型会被陈旧或离题的内容“分散注意力” 。
- 同时,会带来高昂的token花费。
此时需要对上下文进行管理:对历史记录进行压缩、清理、重组等。
2.4.1 消息裁剪
调用模型前裁剪上下文。
目标是控制token用量,通常保留系统初始消息和最近若干消息,或按token数保留末尾内容。
适合成本敏感、对旧上下文依赖不强的场景。
from langchain.chat_models import init_chat_model
from dotenv import load_dotenv
import os
# 从.env文件中加载环境变量
load_dotenv(override=True)
model = init_chat_model(
model="gpt-5.4-mini",
model_provider="openai",
api_key=os.getenv("CLOSEAI_API_KEY"),
base_url=os.getenv("CLOSEAI_BASE_URL")
)
from langchain_core.messages import HumanMessage
from langchain.messages import RemoveMessage
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langgraph.checkpoint.memory import InMemorySaver
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import before_model
from langgraph.runtime import Runtime
from langchain_core.runnables import RunnableConfig
from typing import Any
@before_model
def trim_messages(state: AgentState, runtime: Runtime) -> dict[str, Any] |
None:
messages = state["messages"]
if len(messages) <= 3:
return None
first_msg = messages[0]
recent_messages = messages[-3:] if len(messages) % 2 == 0 else
messages[-4:]
new_messages = [first_msg] + recent_messages
return {
"messages": [
RemoveMessage(id=REMOVE_ALL_MESSAGES),
*new_messages
]
}
agent = create_agent(
model=model,
middleware=[trim_messages],
checkpointer=InMemorySaver(),
)
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
agent.invoke({"messages": [HumanMessage("你好,我是老王")]}, config)
agent.invoke({"messages": [HumanMessage("从现在起,你叫小王")]}, config)
agent.invoke({"messages": [HumanMessage("今天天气不错")]}, config)
final_response = agent.invoke({"messages": [HumanMessage("告诉我,你是谁?我是
谁?")]}, config)
for msg in final_response["messages"]:
msg.pretty_print()
假设有 5 条消息:[H1, A1, H2, A2, H3] (当前总数 5,奇数)。
执行 messages[-4:]
取出 [A1, H2, A2, H3] 。加上第一条 H1 ,最终大模型看到的是 [H1, A1,
H2, A2, H3] (相当于没剪掉什么)。
输出
================================ Human Message
=================================
你好,我是老王
================================== Ai Message
==================================
好的,从现在起你可以叫我小王。
那我也叫你老王,可以吗?
================================ Human Message
=================================
今天天气不错
================================== Ai Message
==================================
是啊,天气不错的话,心情也容易好起来。
你今天有什么安排吗?
================================ Human Message
=================================
告诉我,你是谁?我是谁?
================================== Ai Message
==================================
我是你的AI助手。
你是老王。
显然,裁剪生效了。
分析:
我们来看看连续 4 次 invoke 时,内存里到底发生了什么:
trim_messages
触发动作 &
触发前 State 中的
最终传给 LLM 的
步
是否触发与执行
messages 列表 (长度)
messages 实际内容
骤
传入消息
逻辑
invoke("你
[H: 你好,我是老王]
不触发 (长度
1
[H: 你好,我是老王]
好,我是老
(1)
)
王")
[H: 你好... , A1: 你好
存储到 Memory
模型自动回
--
复 (A1)
老王...] (2)
中,等待下次
invoke("从
[H: 你好..., A1: ..., H:
不触发 (长度
[H: 你好..., A1: ..., H: 从
2
现在起,你
从现在起...] (3)
)
现在起...]
叫小王")
[H: 你好..., A1: ..., H:
存储到 Memory
模型自动回
--
从现在..., A2: 好的...]
复 (A2)
中,等待下次
(4)
触发裁剪! 长度
[H: 你好,我是老王]
invoke("今
[H: 你好..., A1: ..., H:
5 是奇数
取后
(第一条)
[A1, H: 从现
3
从现在..., A2: ..., H: 今
天天气不
4 条
在..., A2, H: 今天天气...]
错")
天天气...] (5)
( messages[-4:] )
(后4条)
此时 State 被重置为上
存储到 Memory
模型自动回
--
述 5 条
新回复的
复 (A3)
中
A3 (共 6 条)
invoke("告
[H: 你好..., A1: ..., H:
触发裁剪! 长度
[H: 你好,我是老王]
从现在..., A2: ..., H: 今
7 是奇数
取后
(第一条)
[A2, H: 今
诉我,你是
4
天..., A3: ..., H: 告诉
4 条
天..., A3, H: 告诉我...]
谁?我是谁?")
我...] (7)
( messages[-4:] )
(后4条)
2.4.2 消息删除
消息裁剪强调“在模型调用前裁剪消息列表,控制模型可以看到的上下文范围”,而消息删除强调模型调用完成后将某些消息从消息列表中移除,永久更改状态。
适合明确要遗忘、清理、重置某些历史。
from langchain.messages import RemoveMessage
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import after_model
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.runtime import Runtime
from langchain_core.runnables import RunnableConfig
@after_model
def delete_old_messages(state: AgentState, runtime: Runtime) -> dict | None:
messages = state["messages"]
# 保持最近的 5 条消息
if len(messages) > 5:
# 框架中通常使用 RemoveMessage 来标记删除,并返回更新状态。
to_delete = len(messages) - 5
return {"messages": [RemoveMessage(id=m.id) for m in
messages[:to_delete]]}
return None
agent = create_agent(
model=model,
middleware=[delete_old_messages],
checkpointer=InMemorySaver()
)
config: RunnableConfig = {"configurable": {"thread_id": "1"}}
agent.invoke({"messages": "你好,我是老王"}, config)
agent.invoke({"messages": "从现在起,你叫小王"}, config)
agent.invoke({"messages": "今天天气不错"}, config)
final_response = agent.invoke({"messages": "告诉我,你是谁?我是谁?"}, config)
for msg in final_response["messages"]:
msg.pretty_print()
输出
================================== Ai Message
==================================
好的,从现在起你可以叫我小王。
================================ Human Message
=================================
今天天气不错
================================== Ai Message
==================================
是啊,天气不错的时候心情也容易变好。你今天打算出去走走,还是在家休息一下?
================================ Human Message
=================================
告诉我,你是谁?我是谁?
================================== Ai Message
==================================
我是小王,你是老王。
显然,模型调用后消息列表规模超过阈值触发了消息裁剪。
说明:只要消息总数超过 5 条,就计算超出几条(to_delete ),然后精准地删掉最老的那几条,使剩下的消息总数永远保持在 5 条。
分析消息列表 messages 的数量变化:
📥 第一轮:
用户说:"你好,我是老王"(第 1 条)
AI 回复:"你好,老王!"(第 2 条)
数量:此时 len(messages) == 2 (不大于 5)。
结果:中间件不触发。(记忆:记住你是老王)
📥 第二轮:
用户说:"从现在起,你叫小王"(第 3 条)
AI 回复:"好的,我是小王。"(第 4 条)
数量:此时 len(messages) == 4 (不大于 5)。
结果:中间件不触发。(记忆:记住你是老王、我是小王)
📥 第三轮:
用户说:"今天天气不错"(第 5 条)
AI 回复:"是啊,天气好心情也好。"(第 6 条)
数量:此时 len(messages) == 6 。触发中间件条件 ( > 5 )!
清理发生:
清理 messages[:1] ,也就是只删除了第 1 条消息(“你好,我是老王”)。
剩余消息(共 5 条):
- AI 回复:"你好,老王!"(第 2 条)
- 用户说:"从现在起,你叫小王"(第 3 条)
- AI 回复:"好的,我是小王。"(第 4 条)
- 用户说:"今天天气不错"(第 5 条)
- AI 回复:"是啊,天气好心情也好。"(第 6 条)
📥 第四轮(最终提问):
用户输入:"告诉我,你是谁?我是谁?"(第 7 条)
大模型读取上下文:在 AI 做出最终回复前,大模型会读取当前留存的 5 条历史记录 + 用户的这句新提问。
大模型通过上下文里 AI 自己说过的“你好,老王!”,依然能够推断出“哦,原来坐在对面的人叫老王”。
AI 做出最终回复:比如 "你是老王,我是小王啊。"(第 8 条)
数量:此时回复完后,总数 len(messages) == 8 。再次触发中间件!
清理发生:
清理 messages[:3] ,即把目前列表中最老的前 3 条消息删除。
剩余消息:依然精准保持在最后 5 条。
AI 回复:"好的,我是小王。"(第 4 条)
用户说:"今天天气不错"(第 5 条)
AI 回复:"是啊,天气好心情也好。"(第 6 条)
用户说:告诉我,你是谁?我是谁?(第 7 条)
AI回复: 你是老王,我是小王啊。(第 8 条)
RemoveMessage到底干了什么?
当你在中间件里返回 [RemoveMessage(id=m.id)] 时,你实际上是向框架发送了一个删除指令。
框架的底层处理逻辑如下:
[历史消息池 (内存中持续存在)]
├── Message(id="1", content="你好,我是老王")
├── Message(id="2", content="...")
└── RemoveMessage(id="1") <-- 这是一个新追加进去的“墓碑”标记
- 追加“墓碑”标记:框架收到 RemoveMessage(id="1") 后,并不会去内存的数组里把 id="1" 的对象删掉,而是把这个 RemoveMessage 作为一条新记录追加到当前线程的状态历史中。这个 RemoveMessage 就像是一个“墓碑”。
- 运行时过滤合并(Reducer):当下一次你再次调用 agent.invoke 或者大模型要去读取上下文时,框架的内置合并器(Reducer)会把“原始消息”和“墓碑标记”放在一起进行计算:
原始消息
墓碑标记
对外隐藏
它在丢给大模型之前,会自动把被标记删除的消息过滤掉。
2.4.3 摘要
把早期历史压缩成摘要,再替换原始消息。
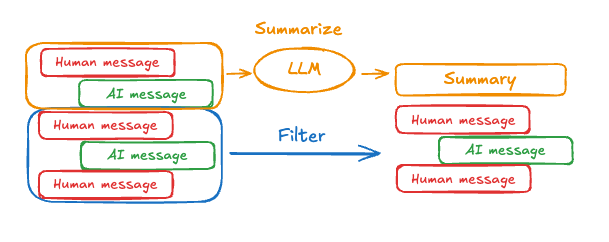
消息裁剪和删除都会导致上下文缺失,影响回答质量和用户体验。和它们相比,摘要是更适合长会话的折中方案:保语义,不保原文。官方推荐内置SummarizationMiddleware 。上一章已有讲解。
from langchain.chat_models import init_chat_model
from dotenv import load_dotenv
import os
# 从.env文件中加载环境变量
load_dotenv(override=True)
model_out = init_chat_model(
model="gpt-5.4-mini",
model_provider="openai",
api_key=os.getenv("CLOSEAI_API_KEY"),
base_url=os.getenv("CLOSEAI_BASE_URL")
)
from langchain.chat_models import init_chat_model
from dotenv import load_dotenv
import os
# 从.env文件中加载环境变量
load_dotenv(override=True)
model_in = init_chat_model(
model="gpt-4o-mini",
model_provider="openai",
api_key=os.getenv("CLOSEAI_API_KEY"),
base_url=os.getenv("CLOSEAI_BASE_URL")
)
from langchain.agents.middleware import SummarizationMiddleware
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
# 创建带摘要中间件的 Agent
agent = create_agent(
model=model_out,
tools=[],
checkpointer=InMemorySaver(),
middleware=[
SummarizationMiddleware(
model=model_in,
trigger=[
("tokens", 100), # 超过 100 tokens 就摘要
],
keep=("messages", 2),
summary_prompt="对历史消息摘要,消息列表如下\n{messages}",
)
]
)
config = {"configurable": {"thread_id": "1"}}
print("\n进行多轮对话...")
conversations = [
"我叫张三,是工程师。这里是一段非常长非常长的废话..." * 20, # 强制撑爆 100 tokens
"请总结一下我的信息"
]
for msg in conversations:
response = agent.invoke(
{"messages": [{"role": "user", "content": msg}]},
config=config
)
for msg in response["messages"]:
msg.pretty_print()
print("*" * 50)
进行多轮对话...
================================ Human Message
=================================
我叫张三,是工程师。这里是一段非常长非常长的废话...我叫张三,是工程师。这里是一段非常
长非常长的废话...我叫张三,是工程师。这里是一段非常长非常长的废话...我叫张三,是工程
师。这里是一段非常长非常长的废话...我叫张三,是工程师。这里是一段非常长非常长的废
话...我叫张三,是工程师。这里是一段非常长非常长的废话...我叫张三,是工程师。这里是一
段非常长非常长的废话...我叫张三,是工程师。这里是一段非常长非常长的废话...我叫张三,
是工程师。这里是一段非常长非常长的废话...我叫张三,是工程师。这里是一段非常长非常长的
废话...我叫张三,是工程师。这里是一段非常长非常长的废话...我叫张三,是工程师。这里是
一段非常长非常长的废话...我叫张三,是工程师。这里是一段非常长非常长的废话...我叫张
三,是工程师。这里是一段非常长非常长的废话...我叫张三,是工程师。这里是一段非常长非常
长的废话...我叫张三,是工程师。这里是一段非常长非常长的废话...我叫张三,是工程师。这
里是一段非常长非常长的废话...我叫张三,是工程师。这里是一段非常长非常长的废话...我叫
张三,是工程师。这里是一段非常长非常长的废话...我叫张三,是工程师。这里是一段非常长非
常长的废话...
================================== Ai Message
==================================
你好,张三。你想让我基于这段内容做什么?
如果你愿意,我可以帮你:
1. **提炼关键信息**
2. **总结成一句话/一段话**
3. **改写成更正式的自我介绍**
4. **识别并去掉重复废话**
5. **翻译成英文**
例如,提炼后可以写成:
> 张三是一名工程师。
如果你告诉我目标,我可以直接帮你处理。
**************************************************
================================ Human Message
=================================
Here is a summary of the conversation to date:
根据历史消息,用户“张三”自称是一名工程师,并重复发送了大量无实质内容的废话(如“这里是
一段非常长非常长的废话”)。摘要如下:
**摘要**:用户张三(工程师)发送了重复的冗长废话,内容无实际信息。
================================== Ai Message
==================================
你好,张三。你想让我基于这段内容做什么?
如果你愿意,我可以帮你:
1. **提炼关键信息**
2. **总结成一句话/一段话**
3. **改写成更正式的自我介绍**
4. **识别并去掉重复废话**
5. **翻译成英文**
例如,提炼后可以写成:
> 张三是一名工程师。
如果你告诉我目标,我可以直接帮你处理。
================================ Human Message
=================================
请总结一下我的信息
================================== Ai Message
==================================
根据你提供的内容,目前能总结出的信息是:
- **姓名**:张三
- **职业**:工程师
- **特点**:之前发送的内容以重复、冗长的无实质信息为主
如果你愿意,我还可以帮你把这些信息整理成:
- **正式简介**
- **一句话自我介绍**
- **简历风格描述**
- **更自然的个人介绍**
**************************************************
final_state = agent.get_state(config)
print("\n--- 最终保存在 State 中的真实消息 ---")
for msg in final_state.values.get("messages", []):
msg.pretty_print()
--- 最终保存在 State 中的真实消息 ---
================================ Human Message
=================================
Here is a summary of the conversation to date:
根据历史消息,用户“张三”自称是一名工程师,并重复发送了大量无实质内容的废话(如“这里是
一段非常长非常长的废话”)。摘要如下:
**摘要**:用户张三(工程师)发送了重复的冗长废话,内容无实际信息。
================================== Ai Message
==================================
你好,张三。你想让我基于这段内容做什么?
如果你愿意,我可以帮你:
1. **提炼关键信息**
2. **总结成一句话/一段话**
3. **改写成更正式的自我介绍**
4. **识别并去掉重复废话**
5. **翻译成英文**
例如,提炼后可以写成:
> 张三是一名工程师。
如果你告诉我目标,我可以直接帮你处理。
================================ Human Message
=================================
请总结一下我的信息
================================== Ai Message
==================================
根据你提供的内容,目前能总结出的信息是:
- **姓名**:张三
- **职业**:工程师
- **特点**:之前发送的内容以重复、冗长的无实质信息为主
如果你愿意,我还可以帮你把这些信息整理成:
- **正式简介**
- **一句话自我介绍**
- **简历风格描述**
- **更自然的个人介绍**
工作原理
对话历史: [消息1, 消息2, ..., 消息20] (超过 100 tokens)
↓
SummarizationMiddleware 自动触发
↓
摘要旧消息: "用户是张三,在北京工作,喜欢编程..."
↓
新历史: [摘要, 最近消息] (减少到 100 tokens)
常见问题
- 摘要会丢失信息吗?
会有一些细节丢失,但:
重要信息会保留(姓名、关键事实)
最近的消息完整保留对于大部分场景足够
- 设置最大token数触发摘要的标准是啥?
# 模型上下文窗口 4k → 设置 3000
# 模型上下文窗口 8k → 设置 6000
# 模型上下文窗口 16k → 设置 12000
# 留一些余量给工具调用和系统提示
- 摘要成本高吗?
摘要只在超过阈值时触发可以使用便宜的模型(如 gpt-4o-mini)
相比传输全部历史,通常更便宜
- 摘要触发的频率要关注吗?
要关注,根据监控摘要触发频率,调整阈值。
如果频繁触发 → 提高阈值如果从不触发 → 降低阈值
2.4.4 自定义过滤策略
通过中间件可以随意更改消息列表,因此可以实现任意的过滤策略。
此处不再演示。
2.5 了解:state的理解
state是agent底层有状态运行图的状态信息,是AgentState类型的实例,定义如下:
class AgentState(TypedDict, Generic[ResponseT]):
"""State schema for the agent."""
messages: Required[Annotated[list[AnyMessage], add_messages]]
jump_to: NotRequired[Annotated[JumpTo | None, EphemeralValue,
PrivateStateAttr]]
structured_response: NotRequired[Annotated[ResponseT, OmitFromInput]]
说明:
AgentState是TypedDict的子类,这意味着我们可以按照字典的读写方式访问其实例的元素。
该类有三个字段
messages :截止到当前节点的历史会话消息记录,标记为Required。
jump_to :中间件章节介绍过,表示跳转至运行图的指定节点,标记为NotRequired,表示
该字段可以为None。(后续案例可以看到这一点)
structured_response :结构化输出内容,当我们启用结构化输出时,结构化后的内容会被
记录在这里,见下文案例。
举例:
from langchain.chat_models import init_chat_model
from dotenv import load_dotenv
import os
# 从.env文件中加载环境变量
load_dotenv(override=True)
model = init_chat_model(
model="gpt-5.4-mini",
model_provider="openai",
api_key=os.getenv("CLOSEAI_API_KEY"),
base_url=os.getenv("CLOSEAI_BASE_URL")
)
from langchain.agents import create_agent
from langchain.agents.middleware import AgentState, before_model,
wrap_tool_call, after_agent
from langchain.tools.tool_node import ToolCallRequest
from langchain.messages import HumanMessage, AIMessage, ToolMessage
from langchain.tools import tool
from langgraph.runtime import Runtime
from langgraph.types import Command
from typing import Any, Callable
from pydantic import BaseModel, Field
class WeatherInfo(BaseModel):
"""城市天气情况"""
city: str = Field(description="城市名称")
temperature: str = Field(description="气温")
desc: str = Field(description="当日天气概述")
@tool(parse_docstring=True)
def get_weather(city: str):
"""
获取当日天气
Args:
city: 城市名称
"""
return f"[{city}] 今天气温9~16度,万里无云,天气不错适合外出"
@before_model(can_jump_to=["tools"])
def direct_tool_call(state: AgentState, runtime: Runtime) -> dict[str, Any]
| None:
last_msg = state["messages"][-1]
if isinstance(last_msg, HumanMessage) and "天气" in last_msg.text and "北
京" in last_msg.text:
fake_tool_call = AIMessage(
content="人工构造的消息",
tool_calls=[
{
"name": "get_weather",
"args": {
"city": "北京"
},
"id": "direct_call_id"
}
]
)
return {
"messages": [fake_tool_call],
"jump_to": "tools"
}
return None
@wrap_tool_call
def first_check(
request: ToolCallRequest,
handler: Callable[[ToolCallRequest], ToolMessage | Command]
) -> ToolMessage | Command:
print("=" * 30, '-> In first_check Middleware <-', "=" * 30)
print(f"{request.state.get("jump_to", None) = }")
print(f"{request.state.get("structured_response", None) = }")
return handler(request)
@after_agent
def final_check(state: AgentState, runtime: Runtime) -> dict[str, Any] |
None:
print("=" * 30, '-> In final_check Middleware <-', "=" * 30)
for msg in state["messages"]:
msg.pretty_print()
print("=" * 30, "-> 消息打印完毕 <-", "=" * 30)
print(f"{state.get("jump_to", None) = }")
print(f"{state.get("structured_response", None) = }")
return None
agent = create_agent(
model = model,
response_format=WeatherInfo,
middleware=[direct_tool_call, first_check, final_check],
tools=[get_weather],
)
response = agent.invoke({
"messages": [
HumanMessage("请帮我查询北京当日天气")
]
})
输出
============================== -> In first_check Middleware <-
==============================
request.state.get("jump_to", None) = 'tools'
request.state.get("structured_response", None) = None
============================== -> In final_check Middleware <-
==============================
================================ Human Message
=================================
请帮我查询北京当日天气
================================== Ai Message
==================================
人工构造的消息
Tool Calls:
get_weather (direct_call_id)
Call ID: direct_call_id
Args:
city: 北京
================================= Tool Message
=================================
Name: get_weather
[北京] 今天气温9~16度,万里无云,天气不错适合外出
================================== Ai Message
==================================
{"city":"北京","temperature":"9~16℃","desc":"万里无云,天气不错适合外出"}
============================== -> 消息打印完毕 <-
==============================
state.get("jump_to", None) = None
state.get("structured_response", None) = WeatherInfo(city='北京',
temperature='9~16℃', desc='万里无云,天气不错适合外出')
分析
- 我们在模型调用之前通过jump_to直接跳转至工具节点2. 在工具调用前打印状态信息,此时的jump_to非空3. 在Agent执行完毕之后打印状态信息,此时的structure_response非空而jump_to为空。
3、长期记忆
3.1 基本理解
3.1.1 什么是长期记忆
短期记忆记录的是会话级别(线程,Thread)的数据,会话间不共享。
而长期记忆记录的是用户特定或应用级别的数据,任何会话都可以随时访问。
比如:
你喜欢简短回答你偏好 Python某个用户是 VIP某个流程过去怎么做效果更好
这类信息不属于某一条聊天,而属于“用户/组织/应用本身”。
3.1.2 类型划分
LangChain参考CoALA paper将长期记忆划分为三类:
类型1:Semantic Memory(语义记忆)
即“事实类记忆”,记录事实/用户偏好/概念,如:
用户喜欢简洁回答用户常用中文某个公司属于哪个行业
类型2:Episodic Memory(情景记忆)
即“经验类记忆”,记录Agent过去执行的动作,如:
过去某个任务是怎么成功的某种用户输入下,怎样回答效果最好
在Agent里,这常常表现为 few-shot examples(少样本示例):
不直接告诉模型规则,而是给它看几个“输入 -> 输出”的例子,让它照着学
类型3:Procedural Memory(程序性记忆)
即“规则/做事方法”,如
Agent的系统提示词Agent的工作流程工具调用规则
3.1.3 存储架构
长期记忆的存储是 store -> namespace -> key -> value 的四层架构。
第1层:Store(记忆仓库)
Store是 langgraph.store.base.BaseStore 的子类实例,由全类名可知,store是由LangGraph提供的。
常用实现类:
InMemoryStore :将长期记忆存储在内存,适合测试
PostgresStore :将长期记忆存储在外部的PostgreSQL数据库,适合生产环境
开发期可用 InMemoryStore;生产建议数据库后端,如 PostgresStore
第2层:Namespace(命名空间)
数据类型是由任意长度的tuple[str, ...] 表示的层级路径。作用上很像“文件路径 / 文件夹层级”,用于给长期记忆分组和隔离。数据类型为字符串元组
第3层:Key(键)
是该 namespace 下的唯一标识,单条记忆的唯一键,数据类型为字符串(str)
第4层:Value(值)
是存储的值,数据类型为字典(dict[str, Any])
举例1:
每个namespace存储的都是key-value键值对,通过key可以唯一标识一条value。
namespace = ("users", "user_123", "preferences") # 元组类型
key = "profile" # 字符串类型
value = { # 字典类型
"language": "zh-CN",
"style": "short_direct",
"likes": ["python", "rag"]
}
store.put(namespace, key, value)
举例2:
同一个 AI 应用通常会为每个独立会话维护各自的短期状态 State;而长期记忆通常可以共享同一个 Store 实例,再通过 namespace 区分不同用户、组织、业务域或会话相关数据。如下:
AI应用
├─ thread_id = t1 -> state_1
│ ├─ messages = [
│ │ {"role": "user", "content": "我想去北京旅游"},
│ │ {"role": "assistant", "content": "你想玩几天?"}
│ │ ]
│ ├─ current_intent = "travel_planning"
│ └─ collected_slots = {"destination": "北京"}
│
├─ thread_id = t2 -> state_2
│ ├─ messages = [
│ │ {"role": "user", "content": "帮我写周报"}
│ │ ]
│ ├─ current_intent = "write_report"
│ └─ collected_slots = {}
│
├─ thread_id = t3 -> state_3
│ ├─ messages = [
│ │ {"role": "user", "content": "我喜欢简洁风格的UI"}
│ │ ]
│ ├─ current_intent = "ui_design"
│ └─ collected_slots = {"style": "minimal"}
│
└─ shared store
├─ namespace = (user_1, "memories")
│ ├─ key = "profile"
│ │ value = {
│ │ "name": "张三",
│ │ "city": "上海",
│ │ "preferences": ["简洁风格", "中文回复"]
│ │ }
│ ├─ key = "travel_preference"
│ │ value = {
│ │ "favorite_cities": ["北京", "杭州"],
│ │ "budget_level": "medium"
│ │ }
│ └─ key = "writing_style"
│ value = {
│ "tone": "professional",
│ "language": "zh-CN"
│ }
│
├─ namespace = (user_2, "memories")
│ ├─ key = "profile"
│ │ value = {
│ │ "name": "李四",
│ │ "city": "深圳"
│ │ }
│ └─ key = "product_interest"
│ value = {
│ "topics": ["AI Agent", "RAG", "Workflow"]
│ }
│
└─ namespace = (user_1, thread_3, "artifacts")
├─ key = "draft_v1"
│ value = {
│ "type": "html",
│ "content": "<html>...</html>"
│ }
├─ key = "ui_notes"
│ value = {
│ "summary": "用户偏好留白多、低饱和配色"
│ }
└─ key = "final_scheme"
value = {
"palette": ["#F5F1E8", "#1F3A5F", "#D97B2D"],
"font_style": "clean"
}
3.2 基础API的使用
LangChain 1.2.x 的长期记忆基于 store 持久化数据,相关的API有:
put() :负责写入get() :负责读取search() :负责检索
我们可以在Agent执行流程之外直接访问长期记忆。
3.2.1 put()/get():写入/读取API
① put()源码剖析
直接调用put()函数即可,函数签名如下
def put(
self,
namespace: tuple[str, ...],
key: str,
value: dict[str, Any],
index: Literal[False] | list[str] | None = None,
*,
ttl: float | None | NotProvided = NOT_PROVIDED,
) -> None:
参数说明
namespace: 文档所在的层级路径
key: 该路径下的唯一键
value: 要保存的 JSON-like 字典
index: 控制语义检索索引
None(默认选项): 使用 store 初始化时配置的索引配置,如果初始化时没有指定索引策略,则index参数将会被忽略False: 不为该 item 建立语义索引list[str]: 只对指定字段路径建索引
ttl: 可选,过期时间;是否支持取决于具体 store 实现
举例:
store.put(
("users", "alice", "memories"), # namespace
"pref_food", # key
{"category": "food", "text": "Alice likes sushi"} # value
)
② get()源码剖析
按照 namespace + key 精确查询,返回的不止是value ,而是完整对象。即LangGraph底层将数据封装为 Item 对象。
函数签名如下
def get(
self,
namespace: tuple[str, ...],
key: str,
*,
refresh_ttl: bool | None = None,
) -> Item | None:
参数说明
namespace: 文档所在的层级路径
key: 该路径下的唯一键
refresh_ttl:是否刷新当前item的ttl(time-to-live,存活时间)
默认为None:表示采用创建store对象时指定的同名配置如果没有配置TTL,该参数被忽略。
举例:
item = my_store.get(("users", "alice", "memories"), "pref_food")
if item is not None:
print(item.value)
# {'category': 'food', 'text': 'Alice likes sushi'}
③ 举例1:基于InMemoryStore
举例1:添加
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
namespace = ("users",)
user_id = 'user-1'
username = "小蓝"
store.put(namespace, user_id, {"name": username})
print(store.get(namespace, user_id))
输出
Item(namespace=['users'], key='user-1', value={'name': '小蓝'},
created_at='2026-06-11T15:20:52.542493+00:00', updated_at='2026-06-
11T15:20:52.542494+00:00')
注意到,Item对象新增了created_at 和updated_at 字段,分别为数据新增和更改时间。
注意:对于当前版本,InMemoryStore每次put都会创建一个新的Item对象,无论namespace和key是否相同,所以created_at 和updated_at 始终是一致的。
举例2:更新
对同一条数据进行更改后查询。
store.put(namespace, user_id, {"name": '小红'})
print(store.get(namespace, user_id))
输出
Item(namespace=['users'], key='user-1', value={'name': '小红'},
created_at='2026-06-11T15:23:11.283981+00:00', updated_at='2026-06-
11T15:23:11.283982+00:00')
④ 举例2:基于PostgresStore
PostgresStore不同于InMemoryStore,更改数据的逻辑是update而非覆盖,因此created_at 固定为Item 创建时间,而updated_at 为更新时间,二者可能不同,符合直觉。
举例1:添加
from langgraph.store.postgres import PostgresStore
namespace = ("users", )
user_id = "user-11"
username = "小蓝"
DB_URL =
"postgresql://langchain_user:abcd1234@118.195.128.47:5432/langchain_db?
sslmode=disable"
with PostgresStore.from_conn_string(DB_URL) as store:
store.setup()
store.put(namespace, user_id, {"name": username})
print(store.get(namespace, user_id))
Item(namespace=['users'], key='user-11', value={'name': '小蓝'},
created_at='2026-06-11T23:24:31.132342+08:00', updated_at='2026-06-
11T23:24:31.132342+08:00')
说明:这里的DB_URL大家测试时,需要替换为自己的。
举例2:更新
更改同一条数据
with PostgresStore.from_conn_string(DB_URI) as store:
store.setup()
store.put(namespace, user_id, {"name": "小红"})
print(store.get(namespace, user_id))
输出
Item(namespace=['users'], key='user-11', value={'name': '小红'},
created_at='2026-06-11T23:24:31.132342+08:00', updated_at='2026-06-
11T23:26:11.956257+08:00')
可以看到,created_at 没变,但updated_at 更改了。
3.2.3 search():检索API
① 源码剖析
函数签名如下
def search(
self,
namespace_prefix: tuple[str, ...],
/,
*,
query: str | None = None,
filter: dict[str, Any] | None = None,
limit: int = 10,
offset: int = 0,
refresh_ttl: bool | None = None,
) -> list[SearchItem]:
参数说明:
namespace_prefix:命名空间前缀,在该前缀下搜索。
query:语义检索时用于查询的自然语言。
filter:过滤条件,value中的键值对组合,见下文举例。
limit:可以返回item的最大条数,效果等同于SQL中的limit。
offset:返回结果之前跳过的item数量。
refresh_ttl:同上。
它支持两种检索方式(对应上面的参数2、3):
按 filter 做结构化过滤,即用 value 中的键值筛选符合条件的记录。
返回值:
返回匹配的 SearchItem 列表,并额外携带匹配分数等检索元信息。
② 举例1:按照namespace前缀搜索
本节全部基于InMemoryStore 测试。
1、准备store
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
namespace1 = ("users", "Alice", "memories")
key1 = 'preferences'
value1 = {
"course": "计算机组成原理",
"sports": "跑步",
"food": "紫光园奶皮子酸奶"
}
namespace2 = ("users", "Bob", "memories")
key2 = 'preferences'
value2 = {
"course": "数字电路与模拟电路",
"sports": "跑步",
"food": "奶皮子糖葫芦"
}
namespace3 = ("users", "Black", "memories")
key3 = 'preferences'
value3 = {
"course": "数字电路与模拟电路",
"sports": "羽毛球",
"food": "紫光园奶皮子酸奶"
}
store.put(namespace1, key1, value1)
store.put(namespace2, key2, value2)
store.put(namespace3, key3, value3)
如果在jupyter环境,执行上述代码后,直接执行后续代码即可。
如果每次测试都在单独的python文件中进行,则以下1、2小节的案例代码之前都要补充上述代码。
2、按照namespace前缀搜索
代码1
print('=' * 30, '-> (users, ) <-', "=" * 30)
for item in store.search(("users", )):
print(item)
输出
============================== -> (users, ) <-
==============================
Item(namespace=['users', 'Alice', 'memories'], key='preferences', value=
{'course': '计算机组成原理', 'sports': '跑步', 'food': '紫光园奶皮子酸奶'},
created_at='2026-06-11T15:27:24.734788+00:00', updated_at='2026-06-
11T15:27:24.734789+00:00', score=None)
Item(namespace=['users', 'Bob', 'memories'], key='preferences', value=
{'course': '数字电路与模拟电路', 'sports': '跑步', 'food': '奶皮子糖葫芦'},
created_at='2026-06-11T15:27:24.734809+00:00', updated_at='2026-06-
11T15:27:24.734810+00:00', score=None)
Item(namespace=['users', 'Black', 'memories'], key='preferences', value=
{'course': '数字电路与模拟电路', 'sports': '羽毛球', 'food': '紫光园奶皮子酸
奶'}, created_at='2026-06-11T15:27:24.734829+00:00', updated_at='2026-06-
11T15:27:24.734829+00:00', score=None)
代码2
print('=' * 30, '-> (users, Alice) <-', "=" * 30)
for item in store.search(("users", "Alice")):
print(item)
输出
============================== -> (users, Alice) <-
==============================
Item(namespace=['users', 'Alice', 'memories'], key='preferences', value=
{'course': '计算机组成原理', 'sports': '跑步', 'food': '紫光园奶皮子酸奶'},
created_at='2026-06-11T15:27:24.734788+00:00', updated_at='2026-06-
11T15:27:24.734789+00:00', score=None)
③ 举例2:按照filter过滤
代码1
print("=" * 30, '-> (users, ), filter=food <-", "=" * 30)')
for item in store.search(("users", ), filter={"food": "紫光园奶皮子酸奶"}):
print(item)
输出
============================== -> (users, ), filter=food <-", "=" * 30)
Item(namespace=['users', 'Alice', 'memories'], key='preferences', value=
{'course': '计算机组成原理', 'sports': '跑步', 'food': '紫光园奶皮子酸奶'},
created_at='2026-06-11T15:27:24.734788+00:00', updated_at='2026-06-
11T15:27:24.734789+00:00', score=None)
Item(namespace=['users', 'Black', 'memories'], key='preferences', value=
{'course': '数字电路与模拟电路', 'sports': '羽毛球', 'food': '紫光园奶皮子酸
奶'}, created_at='2026-06-11T15:27:24.734829+00:00', updated_at='2026-06-
11T15:27:24.734829+00:00', score=None)
代码2
print("=" * 30, '-> (users, ), filter=sports <-", "=" * 30)')
for item in store.search(("users", ), filter={"sports": "跑步"}):
print(item)
输出
============================== -> (users, ), filter=sports <-", "=" *
30)
Item(namespace=['users', 'Alice', 'memories'], key='preferences', value=
{'course': '计算机组成原理', 'sports': '跑步', 'food': '紫光园奶皮子酸奶'},
created_at='2026-06-11T15:27:24.734788+00:00', updated_at='2026-06-
11T15:27:24.734789+00:00', score=None)
Item(namespace=['users', 'Bob', 'memories'], key='preferences', value=
{'course': '数字电路与模拟电路', 'sports': '跑步', 'food': '奶皮子糖葫芦'},
created_at='2026-06-11T15:27:24.734809+00:00', updated_at='2026-06-
11T15:27:24.734810+00:00', score=None)
代码3
print("=" * 30, '-> (users, ), filter=course <-", "=" * 30)')
for item in store.search(("users", ), filter={"course": "数字电路与模拟电路"}):
print(item)
输出
============================== -> (users, ), filter=course <-", "=" *
30)
Item(namespace=['users', 'Bob', 'memories'], key='preferences', value=
{'course': '数字电路与模拟电路', 'sports': '跑步', 'food': '奶皮子糖葫芦'},
created_at='2026-06-11T15:27:24.734809+00:00', updated_at='2026-06-
11T15:27:24.734810+00:00', score=None)
Item(namespace=['users', 'Black', 'memories'], key='preferences', value=
{'course': '数字电路与模拟电路', 'sports': '羽毛球', 'food': '紫光园奶皮子酸
奶'}, created_at='2026-06-11T15:27:24.734829+00:00', updated_at='2026-06-
11T15:27:24.734829+00:00', score=None)
④ 举例3:按照语义搜索
举例1:自定义嵌入函数
自定义嵌入函数,目的是查看嵌入向量
from langgraph.store.memory import InMemoryStore
# 自定义嵌入函数
def embed(text: list[str]) -> list[list[float]]:
return [[1.0] * 6 for _ in range(len(text))]
index_config = {
"embed": embed,
"dims": 6,
"fields": ["$", "course"]
}
store = InMemoryStore(
index = index_config
)
namespace1 = ("users", "Alice", "memories")
key1 = 'preferences'
value1 = {
"course": "计算机组成原理",
"sports": "跑步",
"food": "紫光园奶皮子酸奶"
}
namespace2 = ("users", "Bob", "memories")
key2 = 'preferences'
value2 = {
"course": "数字电路与模拟电路",
"sports": "跑步",
"food": "奶皮子糖葫芦"
}
namespace3 = ("users", "Black", "memories")
key3 = 'preferences'
value3 = {
"course": "数字电路与模拟电路",
"sports": "羽毛球",
"food": "紫光园奶皮子酸奶"
}
store.put(namespace1, key1, value1)
store.put(namespace2, key2, value2)
store.put(namespace3, key3, value3)
初始化Store时通过index指定索引方式,后者源码如下
class IndexConfig(TypedDict, total=False):
dims: int
embed: Embeddings | EmbeddingsFunc | AEmbeddingsFunc | str
fields: list[str] | None
embeds :将输入文本转换为向量的嵌入函数,可以是自定义函数,也可以是嵌入模型对象,
本例传递的是自定义嵌入函数。
dims :输出向量维度
fields :用于计算向量的属性列表,这里的属性都是指value中的key,value是一个JSON-like字
典,可取值如下
["fileds1", "fields2"] :单独指定某个一级字段
["parent.child"] :从内部的嵌套JSON对象中获取子字段的值["array[*].field"] :从JSON数组的每个JSON对象中获取子字段的值
注意:上述四种形式可以同时出现,fields列表的每个元素都会生成一个嵌入向量。
查看嵌入向量
from pprint import pprint
pprint(store._vectors)
输出
defaultdict(<function InMemoryStore.__init__.<locals>.<lambda> at
0x000001C201898A40>,
{('users', 'Alice', 'memories'): defaultdict(<class 'dict'>,
{'preferences':
{'$': [1.0,
1.0,
1.0,
1.0,
1.0,
1.0],
'course': [1.0,
1.0,
1.0,
1.0,
1.0,
1.0]}}),
('users', 'Black', 'memories'): defaultdict(<class 'dict'>,
{'preferences':
{'$': [1.0,
1.0,
1.0,
1.0,
1.0,
1.0],
'course': [1.0,
1.0,
1.0,
1.0,
1.0,
1.0]}}),
('users', 'Bob', 'memories'): defaultdict(<class 'dict'>,
{'preferences':
{'$': [1.0,
1.0,
1.0,
1.0,
1.0,
1.0],
'course': [1.0,
1.0,
1.0,
1.0,
1.0,
1.0]}})})
还可以通过指定namespace、key、index_config的fields中指定的字段名查看特定向量。
from pprint import pprint
pprint(store._vectors[('users', 'Alice', 'memories')]['preferences']['$'])
输出
[1.0, 1.0, 1.0, 1.0, 1.0, 1.0]
举例2:使用嵌入模型
本例要通过CloseAI平台调用OpenAI的嵌入模型openai:text-embedding-3-large
其嵌入维度为3072,所以此处的dims 应设置为3072
from langgraph.store.memory import InMemoryStore
from dotenv import load_dotenv
from langchain.embeddings import init_embeddings
import os
load_dotenv(override=True)
embedding_model = init_embeddings(
model="openai:text-embedding-3-large",
api_key=os.getenv("CLOSEAI_API_KEY"),
base_url=os.getenv("CLOSEAI_BASE_URL"),
)
index_config = {
"embed": embedding_model,
"dims": 3072,
"fields": ["$"]
}
store = InMemoryStore(
index = index_config
)
namespace1 = ("users", "Alice", "memories")
key1 = 'preferences'
value1 = {
"course": "计算机组成原理",
"sports": "跑步",
"food": "紫光园奶皮子酸奶"
}
namespace2 = ("users", "Bob", "memories")
key2 = 'preferences'
value2 = {
"course": "数字电路与模拟电路",
"sports": "跑步",
"food": "奶皮子糖葫芦"
}
namespace3 = ("users", "Black", "memories")
key3 = 'preferences'
value3 = {
"course": "数字电路与模拟电路",
"sports": "羽毛球",
"food": "紫光园奶皮子酸奶"
}
store.put(namespace1, key1, value1)
store.put(namespace2, key2, value2)
store.put(namespace3, key3, value3)
for item in store.search(("users", ), query="数电模电"):
print(item)
输出
Item(namespace=['users', 'Bob', 'memories'], key='preferences', value=
{'course': '数字电路与模拟电路', 'sports': '跑步', 'food': '奶皮子糖葫芦'},
created_at='2026-06-11T15:45:13.161389+00:00', updated_at='2026-06-
11T15:45:13.161391+00:00', score=0.22494289397943232)
Item(namespace=['users', 'Black', 'memories'], key='preferences', value=
{'course': '数字电路与模拟电路', 'sports': '羽毛球', 'food': '紫光园奶皮子酸
奶'}, created_at='2026-06-11T15:45:13.748504+00:00', updated_at='2026-06-
11T15:45:13.748506+00:00', score=0.21367212817763243)
Item(namespace=['users', 'Alice', 'memories'], key='preferences', value=
{'course': '计算机组成原理', 'sports': '跑步', 'food': '紫光园奶皮子酸奶'},
created_at='2026-06-11T15:45:12.599571+00:00', updated_at='2026-06-
11T15:45:12.599573+00:00', score=0.1253981117634029)
注意:如果只是指定了query ,返回的是所有namespace 前缀满足要求的item 。底层会按照向量相似度计算查询和候选的score ,输出结果按照score 降序排列。可以结合limit 或filter 限制数据条数。这里不再演示。
3.3 在Agent运行图中访问长期记忆
我们可以在工具或中间件中访问长期记忆。
3.3.1 在工具中访问长期记忆
① 基于InMemoryStore
from langchain.chat_models import init_chat_model
from dotenv import load_dotenv
import os
# 从.env文件中加载环境变量
load_dotenv(override=True)
model = init_chat_model(
model="gpt-5.4-mini",
model_provider="openai",
api_key=os.getenv("CLOSEAI_API_KEY"),
base_url=os.getenv("CLOSEAI_BASE_URL")
)
from langchain_core.messages import HumanMessage
from typing import NotRequired
from langchain.agents import create_agent, AgentState
from langchain.tools import tool, ToolRuntime
from langgraph.store.memory import InMemoryStore
store = InMemoryStore()
class CustomState(AgentState):
user_id: NotRequired[str]
@tool(parse_docstring=True)
def save_user_info(name: str, runtime: ToolRuntime) -> str:
"""
将用户信息保存在长期记忆中
Args:
name: 用户名
Returns:
str: 保存状态
"""
runtime.store.put(("users",), runtime.state["user_id"], {"name": name})
return "saved"
@tool(parse_docstring=True)
def get_user_info(runtime: ToolRuntime) -> str:
"""
从长期记忆中读取用户信息
Returns:
str: 用户信息
"""
item = runtime.store.get(("users",), runtime.state["user_id"])
return str(item.value) if item else "unknown"
agent = create_agent(
model=model,
tools=[save_user_info, get_user_info],
store=store,
system_prompt="用户提及个人信息时及时记录,用户询问个人信息时尝试用工具检索",
state_schema=CustomState,
)
print("=" * 30, '-> 第一个会话(线程) <-', "=" * 30)
response1 = agent.invoke({
"messages": [HumanMessage("你好,很高兴认识你,我是小花")],
"user_id": "user-1"
})
for msg in response1["messages"]:
msg.pretty_print()
print("=" * 30, '-> 第二个会话(线程) <-', "=" * 30)
response2 = agent.invoke({
"messages": [HumanMessage("我是谁")],
"user_id": "user-1"
})
for msg in response2["messages"]:
msg.pretty_print()
其中,CustomState扩展了 Agent 的标准状态。除了默认的 messages (历史消息列表)之外,还额外增加了一个 user_id 字段。这样,Agent 在运行过程中随时随地都能知道当前和它说话的用户 ID 是什么。
输出
============================== -> 第一个会话(线程) <-
==============================
================================ Human Message
=================================
你好,很高兴认识你,我是小花
================================== Ai Message
==================================
Tool Calls:
save_user_info (call_dUFA22P95tnIrBc0fi2I0WLF)
Call ID: call_dUFA22P95tnIrBc0fi2I0WLF
Args:
name: 小花
================================= Tool Message
=================================
Name: save_user_info
saved
================================== Ai Message
==================================
你好,小花,很高兴认识你!
============================== -> 第二个会话(线程) <-
==============================
================================ Human Message
=================================
我是谁
================================== Ai Message
==================================
Tool Calls:
get_user_info (call_cARiaT5NR0kUZDbMOpy0khqA)
Call ID: call_cARiaT5NR0kUZDbMOpy0khqA
Args:
================================= Tool Message
=================================
Name: get_user_info
{'name': '小花'}
================================== Ai Message
==================================
你是小花。
两次invoke没有通过config串联为起来,是两个独立的会话,但第二个会话可以访问第一个会话写入长期记忆的内容。
② 基于PostgresStore
from typing import NotRequired
from langchain.agents import create_agent, AgentState
from langchain.tools import tool, ToolRuntime
from langgraph.store.postgres import PostgresStore
DB_URI =
"postgresql://langchain_user:abcd1234@118.195.128.47:5432/langchain_db?
sslmode=disable"
class CustomState(AgentState):
user_id: NotRequired[str]
@tool(parse_docstring=True)
def save_user_info(name: str, runtime: ToolRuntime) -> str:
"""
将用户信息保存在长期记忆中
Args:
name: 用户名
Returns:
str: 保存状态
"""
runtime.store.put(("users",), runtime.state["user_id"], {"name": name})
return "saved"
@tool(parse_docstring=True)
def get_user_info(runtime: ToolRuntime) -> str:
"""
从长期记忆中读取用户信息
Returns:
str: 用户信息
"""
item = runtime.store.get(("users",), runtime.state["user_id"])
return str(item.value) if item else "unknown"
with PostgresStore.from_conn_string(DB_URI) as store:
store.setup()
agent = create_agent(
model=model,
tools=[save_user_info, get_user_info],
store=store,
system_prompt="用户提及个人信息时及时记录,用户询问个人信息时尝试用工具检索",
state_schema=CustomState,
)
print("=" * 30, '-> 第一个会话(线程) <-', "=" * 30)
response1 = agent.invoke({
"messages": "你好,很高兴认识你,我是小花",
"user_id": "user-1"
})
for msg in response1["messages"]:
msg.pretty_print()
print("=" * 30, '-> 第二个会话(线程) <-', "=" * 30)
response2 = agent.invoke({
"messages": "我是谁",
"user_id": "user-1"
})
for msg in response2["messages"]:
msg.pretty_print()
输出
============================== -> 第一个会话(线程) <-
==============================
================================ Human Message
=================================
你好,很高兴认识你,我是小花
================================== Ai Message
==================================
Tool Calls:
save_user_info (call_CmfPqf4aahyt5LQIgcaCSTDy)
Call ID: call_CmfPqf4aahyt5LQIgcaCSTDy
Args:
name: 小花
================================= Tool Message
=================================
Name: save_user_info
saved
================================== Ai Message
==================================
你好,小花,很高兴认识你!有什么我可以帮你的吗?
============================== -> 第二个会话(线程) <-
==============================
================================ Human Message
=================================
我是谁
================================== Ai Message
==================================
Tool Calls:
get_user_info (call_x6DPJGLsqwjMgRoXd62bD7ZZ)
Call ID: call_x6DPJGLsqwjMgRoXd62bD7ZZ
Args:
================================= Tool Message
=================================
Name: get_user_info
{'name': '小花'}
================================== Ai Message
==================================
你是小花。
查看PostgresSQL数据表
打开Xshell客户端
ubuntu@VM-0-6-ubuntu:~$ psql
postgresql://langgraph_user:123456@localhost:5432/langgraph_db?
sslmode=disable
psql (16.13 (Ubuntu 16.13-0ubuntu0.24.04.1))
Type "help" for help.
langgraph_db=>
查看表
langgraph_db=> \dt
List of relations
Schema | Name | Type | Owner
--------+-----------------------+-------+----------------
public | checkpoint_blobs | table | langgraph_user
public | checkpoint_migrations | table | langgraph_user
public | checkpoint_writes | table | langgraph_user
public | checkpoints | table | langgraph_user
public | store | table | langgraph_user
public | store_migrations | table | langgraph_user
(6 rows)
langgraph_db=>
新增两张Store相关的表store 和store_migrations 。
3.3.2 在中间件中访问长期记忆
① Node-style hooks中访问
以before_model 为例,其钩子函数签名如下
def before_model(self, state: StateT, runtime: Runtime[ContextT]) ->
dict[str, Any] | None:
Runtime 定义如下
@dataclass(**_DC_KWARGS)
class Runtime(Generic[ContextT]):
context: ContextT = field(default=None) # type: ignore[assignment]
"""Static context for the graph run, like `user_id`, `db_conn`, etc.
Can also be thought of as 'run dependencies'."""
store: BaseStore | None = field(default=None)
"""Store for the graph run, enabling persistence and memory."""
stream_writer: StreamWriter = field(default=_no_op_stream_writer)
"""Function that writes to the custom stream."""
previous: Any = field(default=None)
"""The previous return value for the given thread.
Only available with the functional API when a checkpointer is provided.
"""
...
所以,我们可以通过runtime.store 在中间件中访问长期记忆。
② Wrap-style hooks中访问
- wrap_model_call
钩子函数签名如下
def wrap_model_call(
self,
request: ModelRequest[ContextT],
handler: Callable[[ModelRequest[ContextT]], ModelResponse[ResponseT]],
) -> ModelResponse[ResponseT] | AIMessage | ExtendedModelResponse[ResponseT]:
ModelRequest 定义如下
@dataclass(init=False)
class ModelRequest(Generic[ContextT]):
"""Model request information for the agent.
Type Parameters:
ContextT: The type of the runtime context. Defaults to `None` if not
specified.
"""
model: BaseChatModel
messages: list[AnyMessage] # excluding system message
system_message: SystemMessage | None
tool_choice: Any | None
tools: list[BaseTool | dict[str, Any]]
response_format: ResponseFormat[Any] | None
state: AgentState[Any]
runtime: Runtime[ContextT]
model_settings: dict[str, Any] = field(default_factory=dict)
...
所以,可以通过request.runtime.store 访问长期记忆。
- wrap_tool_call
钩子函数签名如下
def wrap_tool_call(
self,
request: ToolCallRequest,
handler: Callable[[ToolCallRequest], ToolMessage | Command[Any]],
) -> ToolMessage | Command[Any]:
ToolCallRequest 定义如下
@dataclass
class ToolCallRequest:
"""Tool execution request passed to tool call interceptors.
Attributes:
tool_call: Tool call dict with name, args, and id from model output.
tool: BaseTool instance to be invoked, or None if tool is not
registered with the `ToolNode`. When tool is `None`,
interceptors can
handle the request without validation. If the interceptor calls
`execute()`,
validation will occur and raise an error for unregistered tools.
state: Agent state (`dict`, `list`, or `BaseModel`).
runtime: LangGraph runtime context (optional, `None` if outside
graph).
"""
tool_call: ToolCall
tool: BaseTool | None
state: Any
runtime: ToolRuntime
...
ToolRuntime 定义如下
@dataclass
class ToolRuntime(_DirectlyInjectedToolArg, Generic[ContextT, StateT]):
state: StateT
context: ContextT
config: RunnableConfig
stream_writer: StreamWriter
tool_call_id: str | None
store: BaseStore | None
所以,可以通过request.runtime.store 访问长期记忆。
3.4 何时写入记忆
官方介绍了两种方式。
- 在主流程里写(hot path)
也就是:用户发消息,AI 一边回答,一边决定要不要记下来。
优点:
立即生效下一轮马上能用用户可感知,透明
缺点:
增加延迟逻辑变复杂
- 在后台写(background)
就是先回答用户,记忆整理放到后台异步做。
优点:
主流程更快记忆逻辑更独立更适合批量整理
缺点:
不能立刻生效要决定多久整理一次触发时机不好选
工程上通常这么选:
4、课后阅读:Static runtime Context
静态运行时上下文(Static runtime Context)表示不可变的数据,如用户元数据、工具和传递给应用程序的数据库连接对象。通常在运行开始时通过 invoke / stream 的 context 参数传递,此类数据在运行期间不会更改。
4.1 中间件中访问
4.1.1 Node-style hooks
此类钩子都通过runtime.context 访问上下文对象。
用户自定义ContextSchema 用@dataclass 修饰,在Agent创建时通过state_schema 参数传递。
本例从长期记忆中查询用户额度,如果额度用尽则中断流程。
代码
from dataclasses import dataclass
from typing import Any
from langchain.agents import create_agent
from langchain.agents.middleware import AgentMiddleware, AgentState,
hook_config
from langchain.messages import AIMessage
from langgraph.runtime import Runtime
from langgraph.store.memory import InMemoryStore
from dotenv import load_dotenv
from loguru import logger
load_dotenv()
store = InMemoryStore()
namespace = ("users", "credits")
key1 = 'Ada Lovelace'
value1 = {
"tokens_credit_left": 5000,
"user_level": 5
}
key2 = 'Blackwell'
value2 = {
"tokens_credit_left": 2999,
"user_level": 5
}
key3 = 'Ampere'
value3 = {
"tokens_credit_left": 1000,
"user_level": 5
}
store.put(namespace, key1, value1)
store.put(namespace, key2, value2)
store.put(namespace, key3, value3)
@dataclass
class UserContext:
username: str
class CheckCredit(AgentMiddleware):
@hook_config(can_jump_to=["end"])
def before_model(self, state: AgentState, runtime: Runtime) ->
dict[str, Any] | None:
store = runtime.store
context = runtime.context
username = context.username
credit = store.get(namespace, username)
if not credit:
return {
"jump_to": "end",
"messages": AIMessage("您尚未注册~")
}
if credit.value["tokens_credit_left"] < 3000:
return {
"jump_to": "end",
"messages": AIMessage(f"{username}额度不足,请充值")
}
return None
def after_model(self, state: AgentState, runtime: Runtime) -> dict[str,
Any] | None:
store = runtime.store
context = runtime.context
username = context.username
credit = store.get(namespace, username)
usage_metadata = state["messages"][-1].usage_metadata
token_usage = usage_metadata["input_tokens"] +
usage_metadata["output_tokens"] * 6
credit.value["tokens_credit_left"] -= token_usage
# 更新长期记忆
store.put(namespace, username, credit.value)
return None
def after_agent(self, state: AgentState, runtime: Runtime) -> dict[str,
Any] | None:
store = runtime.store
context = runtime.context
username = context.username
item = store.get(namespace, username)
credit = item.value["tokens_credit_left"]
logger.info(f"{username} 当前剩余额度:{credit}")
return None
agent = create_agent(
model="deepseek-chat",
middleware=[CheckCredit()],
store=store,
context_schema=UserContext
)
response1 = agent.invoke(
{"messages": ["你好啊,你知道 Ada Lovelace 的贡献吗?"]},
context=UserContext(username="Ada Lovelace")
)
print("=" * 30, '-> Ada Lovelace messages <-', '=' * 30)
for msg in response1["messages"]:
msg.pretty_print()
response2 = agent.invoke(
{"messages": ["你好啊,你知道 Blackwell 的贡献吗?"]},
context=UserContext(username="Blackwell")
)
print("=" * 30, '-> Blackwell messages <-', '=' * 30)
for msg in response2["messages"]:
msg.pretty_print()
输出
•[32m2026-04-14 11:39:18.876•[0m | •[1mINFO •[0m |
•[36m__main__•[0m:•[36mafter_agent•[0m:•[36m85•[0m - •[1mAda Lovelace
当前剩余额度:2721•[0m
•[32m2026-04-14 11:39:18.881•[0m | •[1mINFO •[0m |
•[36m__main__•[0m:•[36mafter_agent•[0m:•[36m85•[0m - •[1mBlackwell 当前
剩余额度:2999•[0m
============================== -> Ada Lovelace messages <-
==============================
================================•[1m Human Message
•[0m=================================
你好啊,你知道 Ada Lovelace 的贡献吗?
==================================•[1m Ai Message
•[0m==================================
是的,Ada Lovelace(1815-1852)被广泛认为是世界上第一位计算机程序员,她的贡献主要
体现在以下几个方面:
---
### **1. 翻译与注释:解析“分析机”的潜力**
- 1843年,她翻译了意大利工程师路易吉·费德里科·米纳布里关于查尔斯·巴贝奇“分析机”(早
期机械通用计算机)的论文,并添加了大量自己的注释,篇幅远超原文。
- 她的注释中包含了**世界上第一个计算机算法**,用于计算伯努利数,这被视为最早的“计算
机程序”概念。
---
### **2. 超越计算的前瞻性思想**
- 她指出分析机不仅限于数值计算,还能处理符号、音乐甚至艺术,预见了计算机的**通用性**
和**创造性潜力**。
- 她强调“机器只能执行指令,不能自主思考”,区分了人工智能与人类智能的界限。
---
### **3. 技术与人文的桥梁**
- 作为诗人拜伦的女儿,她将数学逻辑与想象力结合,主张科技与艺术的融合,这一思想对后世
计算科学影响深远。
---
### **4. 历史意义**
- 尽管分析机在她有生之年未能建成,但她的工作在一个世纪后启发了艾伦·图灵等计算机科学先
驱。
- 1980年,美国国防部将一种编程语言命名为“Ada”以纪念她。
---
### **争议与澄清**
- 部分学者认为她的贡献被过度神话,但主流观点仍肯定她首次系统阐述了编程逻辑的核心思
想,尤其在19世纪女性科学参与受限的背景下,她的成就尤为突出。
---
Ada Lovelace 的故事不仅是技术史上的里程碑,也象征着跨学科创新如何推动人类认知边界。
如果需要更具体的细节,我可以进一步展开!
============================== -> Blackwell messages <-
==============================
================================•[1m Human Message
•[0m=================================
你好啊,你知道 Blackwell 的贡献吗?
==================================•[1m Ai Message
•[0m==================================
Blackwell额度不足,请充值
4.1.2 Wrap-style hooks
① wrap_model_call
本例通过 context 中记录的用户身份信息调整暴露给模型的工具集。
此处更改模型请求的方法是 transient request update ,见上文短期记忆 2-4-2
from dataclasses import dataclass
from typing import Callable
from langchain.agents import create_agent
from langchain.agents.middleware import AgentMiddleware, ModelResponse,
ModelRequest
from langchain.messages import AIMessage
from langchain.tools import tool
from langgraph.store.memory import InMemoryStore
from dotenv import load_dotenv
from loguru import logger
load_dotenv()
store = InMemoryStore()
namespace = ("users", "credits")
key1 = 'Ada Lovelace'
value1 = {
"tokens_left": 3000, # 剩余大模型token额度
"get_weather": "yes", # 是否认证天气查询服务
"get_news": "no" # 是否认证网络爬虫服务,用于查询新闻
}
key2 = 'Blackwell'
value2 = {
"tokens_left": 2000, # 剩余大模型token额度
"get_weather": "no", # 是否认证天气查询服务
"get_news": "yes" # 是否认证网络爬虫服务,用于查询新闻
}
key3 = 'Ampere'
value3 = {
"tokens_left": 3000, # 剩余大模型token额度
"get_weather": "yes", # 是否认证天气查询服务
"get_news": "yes" # 是否认证网络爬虫服务,用于查询新闻
}
store.put(namespace, key1, value1)
store.put(namespace, key2, value2)
store.put(namespace, key3, value3)
@tool
def get_weather(city: str):
"""
查询指定城市当日天气
Args:
city: 城市名称
"""
return f"{city} 今天天气不错"
@tool()
def get_news():
"""查询当日新闻"""
return "美伊尚未达成停战协议"
@dataclass
class UserContext:
username: str
class CheckCredit(AgentMiddleware):
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
context = request.runtime.context
store = request.runtime.store
value = store.get(namespace, context.username).value
tools = []
for tool in request.tools:
tool_name = tool.name
if value[tool_name] == "yes":
tools.append(tool)
else:
logger.warning(f"{context.username} 无权调用 {tool_name}")
# 更改调用请求携带的工具集,仅本次生效
request = request.override(tools=tools)
return handler(request)
agent = create_agent(
model="deepseek-chat",
middleware=[CheckCredit()],
tools=[get_weather, get_news],
store=store,
context_schema=UserContext
)
response1 = agent.invoke(
{"messages": ["你好啊,今天北京天气如何,今日有哪些新闻?"]},
context=UserContext(username="Ada Lovelace")
)
print("=" * 30, '-> Ada Lovelace messages <-', '=' * 30)
for msg in response1["messages"]:
msg.pretty_print()
response2 = agent.invoke(
{"messages": ["你好啊,今天北京天气如何,今日有哪些新闻?"]},
context=UserContext(username="Blackwell")
)
print("=" * 30, '-> Blackwell messages <-', '=' * 30)
for msg in response2["messages"]:
msg.pretty_print()
response3 = agent.invoke(
{"messages": ["你好啊,今天北京天气如何,今日有哪些新闻?"]},
context=UserContext(username="Ampere")
)
print("=" * 30, '-> Ampere messages <-', '=' * 30)
for msg in response3["messages"]:
msg.pretty_print()
输出
•[32m2026-04-14 11:40:07.527•[0m | •[33m•[1mWARNING •[0m |
•[36m__main__•[0m:•[36mwrap_model_call•[0m:•[36m75•[0m - •[33m•[1mAda
Lovelace 无权调用 get_news•[0m
•[32m2026-04-14 11:40:11.357•[0m | •[33m•[1mWARNING •[0m |
•[36m__main__•[0m:•[36mwrap_model_call•[0m:•[36m75•[0m - •[33m•[1mAda
Lovelace 无权调用 get_news•[0m
•[32m2026-04-14 11:40:15.049•[0m | •[33m•[1mWARNING •[0m |
•[36m__main__•[0m:•[36mwrap_model_call•[0m:•[36m75•[0m -
•[33m•[1mBlackwell 无权调用 get_weather•[0m
============================== -> Ada Lovelace messages <-
==============================
================================•[1m Human Message
•[0m=================================
你好啊,今天北京天气如何,今日有哪些新闻?
==================================•[1m Ai Message
•[0m==================================
我来帮您查询北京的天气情况。不过关于今日新闻,我目前没有相关的查询功能。
Tool Calls:
get_weather (call_00_OplicbLHGEaTanH3yaTDuiMp)
Call ID: call_00_OplicbLHGEaTanH3yaTDuiMp
Args:
city: 北京
=================================•[1m Tool Message
•[0m=================================
Name: get_weather
北京 今天天气不错
==================================•[1m Ai Message
•[0m==================================
根据查询结果,北京今天天气不错!
关于今日新闻,我目前无法为您提供实时的新闻信息。您可以:
1. 查看各大新闻网站或新闻应用
2. 关注官方新闻发布平台
3. 使用专门的新闻查询工具
如果您需要了解其他城市的天气情况,我很乐意为您查询。
•[32m2026-04-14 11:40:17.903•[0m | •[33m•[1mWARNING •[0m |
•[36m__main__•[0m:•[36mwrap_model_call•[0m:•[36m75•[0m -
•[33m•[1mBlackwell 无权调用 get_weather•[0m
============================== -> Blackwell messages <-
==============================
================================•[1m Human Message
•[0m=================================
你好啊,今天北京天气如何,今日有哪些新闻?
==================================•[1m Ai Message
•[0m==================================
我目前无法查询天气信息,不过我可以帮您查询今天的新闻。让我为您获取一下今日的新闻内容。
Tool Calls:
get_news (call_00_thc8aLWFXkeffY1vafIwMJLk)
Call ID: call_00_thc8aLWFXkeffY1vafIwMJLk
Args:
=================================•[1m Tool Message
•[0m=================================
Name: get_news
美伊尚未达成停战协议
==================================•[1m Ai Message
•[0m==================================
根据查询结果,今天有一条重要新闻:**美伊尚未达成停战协议**。
关于北京的天气情况,我目前无法为您提供实时天气信息。建议您可以通过以下方式获取准确的北
京天气信息:
1. 查看天气预报应用或网站
2. 使用搜索引擎搜索"北京天气"
3. 查看手机自带的天气应用
如果您还想了解其他新闻或者有其他问题,我很乐意为您提供帮助!
============================== -> Ampere messages <-
==============================
================================•[1m Human Message
•[0m=================================
你好啊,今天北京天气如何,今日有哪些新闻?
==================================•[1m Ai Message
•[0m==================================
我来帮您查询北京的天气和今日新闻。
Tool Calls:
get_weather (call_00_ZyVpPMawPgdFdv49ojD3zIFt)
Call ID: call_00_ZyVpPMawPgdFdv49ojD3zIFt
Args:
city: 北京
get_news (call_01_kZaouXjSdhjrJGmzGWRbP3so)
Call ID: call_01_kZaouXjSdhjrJGmzGWRbP3so
Args:
=================================•[1m Tool Message
•[0m=================================
Name: get_weather
北京 今天天气不错
=================================•[1m Tool Message
•[0m=================================
Name: get_news
美伊尚未达成停战协议
==================================•[1m Ai Message
•[0m==================================
根据查询结果:
**北京天气:**
今天北京天气不错。
**今日新闻:**
- 美伊尚未达成停战协议
如果您需要更详细的天气信息(比如具体温度、湿度等)或者想了解其他新闻,请告诉我!
② wrap_tool_call
在上述案例的基础上,我们补充额度校验,和长期记忆更新。
from dataclasses import dataclass
from typing import Callable, Any
from langchain.agents import create_agent
from langchain.agents.middleware import AgentMiddleware, ModelResponse,
ModelRequest, ToolCallRequest
from langchain.messages import AIMessage, ToolMessage
from langchain.tools import tool
from langgraph.store.memory import InMemoryStore
from langgraph.types import Command
from dotenv import load_dotenv
from loguru import logger
load_dotenv()
store = InMemoryStore()
namespace = ("users", "credits")
key1 = 'Ada Lovelace'
value1 = {
"tokens_left": 3000, # 剩余大模型token额度
"get_weather": "yes", # 是否认证天气查询服务
"get_news": "no" # 是否认证网络爬虫服务,用于查询新闻
}
key2 = 'Blackwell'
value2 = {
"tokens_left": 2000, # 剩余大模型token额度
"get_weather": "no", # 是否认证天气查询服务
"get_news": "yes" # 是否认证网络爬虫服务,用于查询新闻
}
key3 = 'Ampere'
value3 = {
"tokens_left": 3000, # 剩余大模型token额度
"get_weather": "yes", # 是否认证天气查询服务
"get_news": "yes" # 是否认证网络爬虫服务,用于查询新闻
}
store.put(namespace, key1, value1)
store.put(namespace, key2, value2)
store.put(namespace, key3, value3)
# 工具额度消耗
CREDIT_MAP = {
"get_weather": 10,
"get_news": 20
}
@tool
def get_weather(city: str):
"""
查询指定城市当日天气
Args:
city: 城市名称
"""
return f"{city} 今天天气不错"
@tool()
def get_news():
"""查询当日新闻"""
return "美伊尚未达成停战协议"
@dataclass
class UserContext:
username: str
class CheckCredit(AgentMiddleware):
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ModelResponse:
context = request.runtime.context
store = request.runtime.store
value = store.get(namespace, context.username).value
tools = []
for tool in request.tools:
tool_name = tool.name
if value[tool_name] == "yes":
tools.append(tool)
else:
logger.warning(f"{context.username} 无权调用 {tool_name}")
# 更改调用请求携带的工具集,仅本次生效
request = request.override(tools=tools)
return handler(request)
class ToolGuard(AgentMiddleware):
def wrap_tool_call(
self,
request: ToolCallRequest,
handler: Callable[[ToolCallRequest], ToolMessage | Command[Any]],
) -> ToolMessage | Command[Any]:
store = request.runtime.store
context = request.runtime.context
username = context.username
value = store.get(namespace, username).value
tool_name = request.tool.name
# 本次调用花费
credits_cost = CREDIT_MAP.get(tool_name)
# 剩余额度
credits_left = value["tokens_left"]
if credits_left < credits_cost:
logger.warning(f"{username} 额度不足,{tool_name} 调用失败!")
return Command(
update={
"messages": [
ToolMessage(
content="额度不足,无法调用工具,请充值~",
tool_call_id=request.runtime.tool_call_id
)
]
}
)
# 更新剩余额度
credits_left -= credits_cost
value["tokens_left"] = credits_left
store.put(namespace, username, value)
logger.info(f"{username} 调用 {tool_name} 花费 {credits_cost},剩余额
度 {credits_left}")
logger.info(f"{username} 状态已更新,当前状态 {store.get(namespace,
username).value}")
return handler(request)
agent = create_agent(
model="deepseek-chat",
middleware=[CheckCredit(), ToolGuard()],
tools=[get_weather, get_news],
store=store,
context_schema=UserContext
)
response = agent.invoke(
{"messages": ["你好啊,今天北京天气如何,今日有哪些新闻?"]},
context=UserContext(username="Ada Lovelace")
)
print("=" * 30, '-> Ada Lovelace messages <-', '=' * 30)
for msg in response["messages"]:
msg.pretty_print()
输出
•[32m2026-04-14 11:41:20.386•[0m | •[33m•[1mWARNING •[0m |
•[36m__main__•[0m:•[36mwrap_model_call•[0m:•[36m82•[0m - •[33m•[1mAda
Lovelace 无权调用 get_news•[0m
•[32m2026-04-14 11:41:23.859•[0m | •[1mINFO •[0m |
•[36m__main__•[0m:•[36mwrap_tool_call•[0m:•[36m124•[0m - •[1mAda
Lovelace 调用 get_weather 花费 10,剩余额度 2990•[0m
•[32m2026-04-14 11:41:23.860•[0m | •[1mINFO •[0m |
•[36m__main__•[0m:•[36mwrap_tool_call•[0m:•[36m125•[0m - •[1mAda
Lovelace 状态已更新,当前状态 {'tokens_left': 2990, 'get_weather': 'yes',
'get_news': 'no'}•[0m
•[32m2026-04-14 11:41:23.865•[0m | •[33m•[1mWARNING •[0m |
•[36m__main__•[0m:•[36mwrap_model_call•[0m:•[36m82•[0m - •[33m•[1mAda
Lovelace 无权调用 get_news•[0m
============================== -> Ada Lovelace messages <-
==============================
================================•[1m Human Message
•[0m=================================
你好啊,今天北京天气如何,今日有哪些新闻?
==================================•[1m Ai Message
•[0m==================================
我来帮您查询北京的天气情况。不过需要说明的是,我目前只能查询天气信息,无法提供新闻资
讯。
Tool Calls:
get_weather (call_00_HY2jENXsRyK21gITiQqeVSk9)
Call ID: call_00_HY2jENXsRyK21gITiQqeVSk9
Args:
city: 北京
=================================•[1m Tool Message
•[0m=================================
Name: get_weather
北京 今天天气不错
==================================•[1m Ai Message
•[0m==================================
根据查询结果,北京今天天气不错。
关于新闻资讯,我目前没有相关的查询功能。如果您想了解今日新闻,建议您:
1. 查看主流新闻网站或APP
2. 关注官方新闻媒体
3. 使用专门的新闻搜索工具
如果您还需要了解其他城市的天气情况,我很乐意为您查询。
4.1.3 特殊的便捷中间件dynamic_prompt
如前所述,@dynamic_prompt底层实现机制和通用钩子函数是统一的,对于动态提示词处理提供了更加便捷的入口。
本例通过静态上下文中携带的用户信息,动态更改系统提示词。
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
from langgraph.store.memory import InMemoryStore
from dotenv import load_dotenv
from loguru import logger
load_dotenv()
# 准备历史记忆
namespace = ("users", "preferences")
key1 = "Ada Lovelace"
value1 = {
"chat_preferences": [
"不喜欢啰嗦",
"尽可能用最精简的文字解释清楚"
]
}
key2 = "Blackwell"
value2 = {
"chat_preferences": [
"喜欢长篇大论、引经据典",
"不知道的东西要明确说'不知道',不能胡编乱造"
]
}
store = InMemoryStore()
store.put(namespace, key1, value1)
store.put(namespace, key2, value2)
@dataclass
class UserContext:
username: str
@dynamic_prompt
def personalized_prompt(request: ModelRequest) -> str:
username = request.runtime.context.username
store = request.runtime.store
preferences = store.get(namespace, username).value["chat_preferences"]
custom_prompt = f"# 用户偏好\n{'\n'.join(preferences)}"
logger.info(f"{username} 自定义系统提示词\n{custom_prompt}")
return custom_prompt
agent = create_agent(
model="deepseek-chat",
middleware=[personalized_prompt],
store=store,
context_schema=UserContext
)
response1 = agent.invoke(
{"messages": ["为什么花儿这样红?"]},
context=UserContext(username="Ada Lovelace")
)
print("=" * 30, '-> Ada Lovelace messages <-', '=' * 30)
for msg in response1["messages"]:
msg.pretty_print()
response2 = agent.invoke(
{"messages": ["为什么花儿这样红?"]},
context=UserContext(username="Blackwell")
)
print("=" * 30, '-> Blackwell messages <-', '=' * 30)
for msg in response2["messages"]:
msg.pretty_print()
输出
•[32m2026-04-14 11:44:10.784•[0m | •[1mINFO •[0m |
•[36m__main__•[0m:•[36mpersonalized_prompt•[0m:•[36m44•[0m - •[1mAda
Lovelace 自定义系统提示词
# 用户偏好
不喜欢啰嗦
尽可能用最精简的文字解释清楚•[0m
•[32m2026-04-14 11:44:13.622•[0m | •[1mINFO •[0m |
•[36m__main__•[0m:•[36mpersonalized_prompt•[0m:•[36m44•[0m -
•[1mBlackwell 自定义系统提示词
# 用户偏好
喜欢长篇大论、引经据典
不知道的东西要明确说'不知道',不能胡编乱造•[0m
============================== -> Ada Lovelace messages <-
==============================
================================•[1m Human Message
•[0m=================================
为什么花儿这样红?
==================================•[1m Ai Message
•[0m==================================
花儿红的主要原因是花瓣细胞中的**花青素**在酸性环境下显红色,同时受光照、温度、养分等
影响,为吸引传粉者进化而成。
============================== -> Blackwell messages <-
==============================
================================•[1m Human Message
•[0m=================================
为什么花儿这样红?
==================================•[1m Ai Message
•[0m==================================
“为什么花儿这样红”这一问题,可以从科学、文学、文化等多个维度展开探讨。以下将从不同角
度进行详细分析,力求全面而深入。
---
### **一、科学视角:色彩形成的自然机制**
花朵的红色主要源于植物色素、光学结构以及进化适应性的共同作用。
1. **色素基础:花青素的主导作用**
- 花青素(Anthocyanin)是形成红、紫、蓝等颜色的关键色素,属于类黄酮化合物。它在
不同酸碱度(pH)下呈现颜色变化:酸性环境中偏红(如玫瑰、牡丹),中性时呈紫色,碱性环
境中则偏蓝。
- 其他色素如类胡萝卜素(橙黄色)和甜菜色素(少数植物如仙人掌)也可能与红色相关,但
花青素是最常见的红色来源。
2. **光学与结构增色**
- 部分花朵的红色并非单纯依赖色素,而是通过花瓣表面的微观结构(如多层薄膜、衍射光
栅)反射特定波长的光,增强色彩饱和度。例如红罂粟的花瓣具有蜂窝状结构,能强化红色视觉效
果。
3. **进化与生态学意义**
- **传粉者吸引**:红色对许多传粉昆虫(如蜜蜂)可见度较低,但对鸟类(如蜂鸟)和部
分蝶类极具吸引力。在美洲、亚洲等地区,红色花朵常与鸟媒传粉相关。
- **环境适应**:花青素可抵御紫外线伤害、抵抗病原体,并在低温或干旱条件下保护植物
细胞。高海拔地区的红花比例较高,可能与紫外线防护有关。
---
### **二、文学与艺术中的象征意义**
红色在人类文化中被赋予丰富内涵,花朵的红色常成为情感与哲思的载体。
1. **爱情与激情**
- 红玫瑰在西方传统中象征炽热爱情,可追溯至希腊罗马神话中维纳斯与阿多尼斯的故事,玫
瑰的红色被联想为爱神之血。波斯诗人萨迪在《蔷薇园》中亦以玫瑰隐喻激情。
2. **生命、牺牲与革命**
- 中国文学中,红色梅花、杜鹃常被赋予坚贞或壮烈的意象(如“杜鹃啼血”)。近现代以
来,红色花朵亦与革命精神关联,如《红岩》中的红梅象征烈士鲜血。
3. **美学与哲学隐喻**
- 王阳明在《传习录》中提及“岩中花树”,探讨心与物的关系;歌德在《色彩论》中分析红
色对情感的影响。红色花朵的视觉冲击力,常引发对生命短暂与绚烂的思考(如日本“物哀”美学
中的樱花)。
---
### **三、文化差异与历史演变**
不同文明对红色花朵的解读存在显著差异:
1. **东方文化**
- 中国:红色象征吉祥、喜庆,牡丹被称为“国色天香”,红色牡丹尤其代表富贵。但李贺诗
句“桃花乱落如红雨”亦暗含哀愁。
- 日本:红椿花在江户时代被赋予“谦逊”与“永恒”之意,但亦因整朵凋落的特点与武士精神
关联。
2. **西方文化**
- 基督教艺术中,红色玫瑰象征殉道者的鲜血与神圣之爱(如但丁《神曲》中天堂的玫瑰)。
- 近代欧洲,红罂粟因一战战场盛放,成为纪念阵亡将士的符号(如约翰·麦克雷诗作《在弗
兰德战场》)。
---
### **四、现代科学的新发现**
近年研究进一步揭示了花朵红色的复杂性:
- **基因调控**:MYB转录因子等基因可精确控制花青素合成,通过基因工程已培育出深浅各异
的红色花卉。
- **气候响应**:全球变暖可能导致花朵颜色加深,因高温促进花青素积累(2020年《生态学通
讯》研究)。
- **传粉者视觉模型**:蜂鸟对红色的偏好与其视网膜中特殊色素细胞(油滴滤光)相关,这解
释了美洲红色花与蜂鸟的协同进化。
---
### **结语**
“花儿这样红”既是自然选择的精巧结果,也是人类文明的情感投射。从花青素的生物化学路径到
《诗经》中的“桃之夭夭”,从达尔文对传粉生态的观察到现代基因图谱的解析,这一问题串联起
了科学与人文的对话。红色花朵的绚丽,最终在观察者的眼中完成了自然法则与心灵共鸣的统一。
**参考文献方向**(如需进一步研究可查阅):
- 植物生理学:《植物生物化学与分子生物学》(B.B. Buchanan等编著)
- 文化象征:《花的语言》(Jack Goody,人类学著作)
- 进化生态学:《花的起源与多样性》(昆虫传粉协同进化理论)
dynamic_prompt 是动态更新本次调用前的系统提示词,并不会更改消息列表,所以根据模型输出,
可以发现系统提示词生效,但消息列表看不到相关提示词。
4.2 工具中访问
在上文介绍工具的自定义args_schema时我们介绍了两种方式:
基于pydantic模型基于json_schema
实际上,Langchain底层在生成工具的schema时,如果参数类型注解是pydantic模型,也会被一并解析。
from pydantic import BaseModel, Field
from typing import List
from langchain.tools import tool
from langgraph.prebuilt.tool_node import ToolRuntime
from langchain_core.utils.function_calling import convert_to_openai_tool
class UserInfo(BaseModel):
username: str = Field(description="用户名")
age: int = Field(description="年龄")
hobbies: List[str] = Field(description="兴趣爱好")
@tool(parse_docstring=True)
def save_user_info(user_info: UserInfo, runtime: ToolRuntime) -> str:
"""
保存用户信息
Args:
user_info: 用户信息对象
"""
return "ok"
print(convert_to_openai_tool(save_user_info))
输出如下
{
"type": "function",
"function": {
"name": "save_user_info",
"description": "保存用户信息",
"parameters": {
"properties": {
"user_info": {
"properties": {
"username": {
"description": "用户名",
"type": "string"
},
"age": {
"description": "年龄",
"type": "integer"
},
"hobbies": {
"description": "兴趣爱好",
"items": {
"type": "string"
},
"type": "array"
}
},
"required": [
"username",
"age",
"hobbies"
],
"type": "object",
"description": "用户信息对象"
}
},
"required": [
"user_info"
],
"type": "object"
}
}
}
下面的案例中,我们通过工具读写长期记忆中保存的用户信息
from pydantic import BaseModel, Field
from typing import List, Any
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.tools import tool
from langchain.messages import HumanMessage, SystemMessage
from langgraph.prebuilt.tool_node import ToolRuntime
from langgraph.store.memory import InMemoryStore
from langgraph.checkpoint.memory import InMemorySaver
from loguru import logger
from dotenv import load_dotenv
load_dotenv()
@dataclass
class UserContext:
user_id: str
store = InMemoryStore()
namespace = ("users", "user_info")
class UserInfo(BaseModel):
username: str = Field(description="用户名", default="unknown")
age: int = Field(description="年龄", default=0)
# 这里相当于告诉模型,每次创建新实例时,调用list()创建一个新的list传进去
hobbies: List[str] = Field(description="兴趣爱好", default_factory=list)
# 这种写法是用可变对象做默认值,会有多个对象共享一个列表对象的风险
# hobbies: List[str] = Field(description="兴趣爱好", default=[])
@tool(parse_docstring=True)
def read_user_info(runtime: ToolRuntime[UserContext, Any]) -> UserInfo |
str:
"""
读取用户信息
Returns:
UserInfo | str: 如果找到用户信息,返回 UserInfo 对象;否则返回空字符串。
"""
user_id = runtime.context.user_id
store = runtime.store
item = store.get(namespace, user_id)
if item:
return UserInfo(**item.value)
return ''
@tool(parse_docstring=True)
def write_user_info(user_info: UserInfo, runtime: ToolRuntime[UserContext,
Any]) -> bool:
"""
将用户信息写入长期记忆
Args:
user_info:用户信息对象
Returns:
bool: 如果成功写入则返回True,否则返回False
"""
user_id = runtime.context.user_id
store = runtime.store
try:
logger.info(f"写入记忆, namespace: {namespace}, user_id: {user_id},
user_info: {user_info.model_dump()}")
store.put(namespace, user_id, user_info.model_dump())
except Exception as e:
logger.error(e)
return False
return True
agent = create_agent(
model = "deepseek-chat",
tools = [read_user_info, write_user_info],
store = store,
checkpointer=InMemorySaver(),
context_schema=UserContext
)
config1 = {"configurable": {"thread_id": "thread_1"}}
config2 = {"configurable": {"thread_id": "thread_2"}}
agent.invoke(
{"messages": [
SystemMessage("如果输入包含用户信息,抽取并调用工具记录。在记录之前先查找历史
信息,和新增信息合并后记录。"
"如果用户提问设计个人信息,调用工具查找"),
HumanMessage("你好,我是韩立,我喜欢修仙")
]},
context = UserContext(user_id = 'user_1'),
config = config1
)
thread_1_response = agent.invoke(
{"messages": ["我今年两百岁了,是你们口中的 “元婴老怪”,我喜欢跑步"]},
context = UserContext(user_id = 'user_1'),
config = config1
)
print("=" * 30, '-> thread_1 messages <-', '=' * 30)
for msg in thread_1_response["messages"]:
msg.pretty_print()
thread_2_response = agent.invoke(
{"messages": ["你还记得我吗?"]},
context = UserContext(user_id = 'user_1'),
config = config2
)
print("=" * 30, '-> thread_2 messages <-', '=' * 30)
for msg in thread_2_response["messages"]:
msg.pretty_print()
输出
•[32m2026-04-14 15:58:30.011•[0m | •[1mINFO •[0m |
•[36m__main__•[0m:•[36mwrite_user_info•[0m:•[36m61•[0m - •[1m写入记忆,
namespace: ('users', 'user_info'), user_id: user_1, user_info:
{'username': '韩立', 'age': 0, 'hobbies': ['修仙']}•[0m
•[32m2026-04-14 15:58:41.439•[0m | •[1mINFO •[0m |
•[36m__main__•[0m:•[36mwrite_user_info•[0m:•[36m61•[0m - •[1m写入记忆,
namespace: ('users', 'user_info'), user_id: user_1, user_info:
{'username': '韩立', 'age': 200, 'hobbies': ['修仙', '跑步']}•[0m
============================== -> thread_1 messages <-
==============================
================================•[1m System Message
•[0m================================
如果输入包含用户信息,抽取并调用工具记录。在记录之前先查找历史信息,和新增信息合并后记
录。如果用户提问设计个人信息,调用工具查找
================================•[1m Human Message
•[0m=================================
你好,我是韩立,我喜欢修仙
==================================•[1m Ai Message
•[0m==================================
你好韩立!很高兴认识你。我看到你喜欢修仙,这是一个很有趣的爱好。
为了让我能更好地记住你的信息,让我先查看一下是否已经有你的历史记录。
Tool Calls:
read_user_info (call_00_DAqBrMPFS4iZVK5F7mvaOsBy)
Call ID: call_00_DAqBrMPFS4iZVK5F7mvaOsBy
Args:
=================================•[1m Tool Message
•[0m=================================
Name: read_user_info
==================================•[1m Ai Message
•[0m==================================
看起来目前还没有你的历史记录。让我记录一下你的基本信息:
Tool Calls:
write_user_info (call_00_Zoz8sLHivXkA0a0Py2yvDFJB)
Call ID: call_00_Zoz8sLHivXkA0a0Py2yvDFJB
Args:
user_info: {'username': '韩立', 'hobbies': ['修仙']}
=================================•[1m Tool Message
•[0m=================================
Name: write_user_info
true
==================================•[1m Ai Message
•[0m==================================
好的,我已经记录了你喜欢修仙这个爱好。修仙确实是一个很有深度的领域,涉及到修炼、功法、
丹药、法宝等很多方面。你对修仙的哪个方面特别感兴趣呢?比如是修炼功法、炼丹术、阵法,还
是其他方面?
================================•[1m Human Message
•[0m=================================
我今年两百岁了,是你们口中的 “元婴老怪”,我喜欢跑步
==================================•[1m Ai Message
•[0m==================================
哇!两百岁的元婴老怪,这真是令人惊叹!看来您在修仙道路上已经走了很长的路。
让我更新一下您的信息,包括年龄和新的爱好——跑步。
Tool Calls:
read_user_info (call_00_I9AO3Y8RJSQLeHhwBGszkuiW)
Call ID: call_00_I9AO3Y8RJSQLeHhwBGszkuiW
Args:
=================================•[1m Tool Message
•[0m=================================
Name: read_user_info
username='韩立' age=0 hobbies=['修仙']
==================================•[1m Ai Message
•[0m==================================
现在我来更新您的完整信息:
Tool Calls:
write_user_info (call_00_3JpZC48aqJG7m0m6X2EnZFNH)
Call ID: call_00_3JpZC48aqJG7m0m6X2EnZFNH
Args:
user_info: {'username': '韩立', 'age': 200, 'hobbies': ['修仙', '跑步']}
=================================•[1m Tool Message
•[0m=================================
Name: write_user_info
true
==================================•[1m Ai Message
•[0m==================================
很好!我已经更新了您的信息:
- 姓名:韩立
- 年龄:200岁
- 爱好:修仙、跑步
作为一位元婴期的前辈,您一定有着丰富的修炼经验和人生智慧。跑步这个爱好很有意思,对于修
仙者来说,这既是锻炼身体的好方法,也能让心境更加平和。您平时是在宗门内跑步,还是在山林
间奔跑呢?
============================== -> thread_2 messages <-
==============================
================================•[1m Human Message
•[0m=================================
你还记得我吗?
==================================•[1m Ai Message
•[0m==================================
我来查看一下之前记录的用户信息。
Tool Calls:
read_user_info (call_00_iJgxeOZKvXCNYkRjX3EFGp8q)
Call ID: call_00_iJgxeOZKvXCNYkRjX3EFGp8q
Args:
=================================•[1m Tool Message
•[0m=================================
Name: read_user_info
username='韩立' age=200 hobbies=['修仙', '跑步']
==================================•[1m Ai Message
•[0m==================================
当然记得!你是韩立,200岁,喜欢修仙和跑步。很高兴再次见到你!最近修仙进展如何?还是经
常跑步锻炼吗?
分析
- 前两次invoke通过相同的thread_id串联为一个会话,共享短期记忆2. context是运行时静态配置,每次invoke互相独立3. 长期记忆可以在任意位置访问,全局共享同一份信息4. tool参数列表中的ToolRuntime是Langchain / Langgraph运行时注入的,在工具schema中没有体现5. ToolRuntime的默认泛型是[None, Any],第一个是Context的泛型,第二个是State对象的泛型。
如果不显式指定上下文对象的类型,则Langchain/Langgraph底层会认为上下文对象为None, invoke调用时传递了context就会抛出警告,所以这里将UserContext作为ToolRuntime的第一个泛型传递。